Exploring 67 years of LEGO
The Rebrickable database includes data on every LEGO set that ever been sold; the names of the sets, what bricks they contain, what color the bricks are, etc. It might be small bricks, but this is big data! In this project, you will get to explore the Rebrickable database. To do this you need to know your way around pandas dataframes This is the Result of Project "Exploring 67 years of LEGO", via datacamp.




- 1. Introduction
- 2. Reading Data
- 3. Exploring Colors
- 4. Transparent Colors in Lego Sets
- 5. Explore Lego Sets
- 6. Lego Themes Over Years
- 7. Wrapping It All Up!
1. Introduction
Everyone loves Lego (unless you ever stepped on one). Did you know by the way that "Lego" was derived from the Danish phrase leg godt, which means "play well"? Unless you speak Danish, probably not.
In this project, we will analyze a fascinating dataset on every single lego block that has ever been built!

2. Reading Data
A comprehensive database of lego blocks is provided by Rebrickable. The data is available as csv files and the schema is shown below.
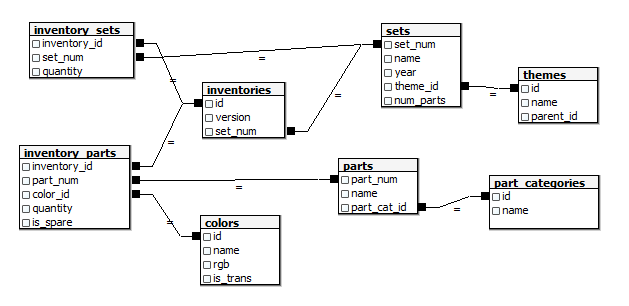
Let us start by reading in the colors data to get a sense of the diversity of lego sets!
import pandas as pd
# Read colors data
colors = pd.read_csv('dataset/colors.csv')
# Print the first few rows
colors.head()
num_colors = len(colors.name.unique())
print(num_colors)
colors_summary = colors.groupby('is_trans').count()
colors_summary
5. Explore Lego Sets
Another interesting dataset available in this database is the sets data. It contains a comprehensive list of sets over the years and the number of parts that each of these sets contained.
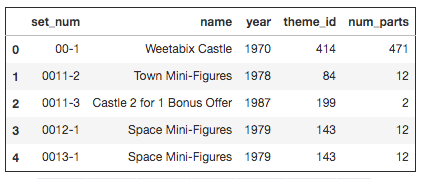
Let us use this data to explore how the average number of parts in Lego sets has varied over the years.
%matplotlib inline
# Read sets data as `sets`
sets = pd.read_csv('./dataset/sets.csv')
# Create a summary of average number of parts by year: `parts_by_year`
parts_by_year = sets.groupby('year').num_parts.mean()
# Plot trends in average number of parts by year
parts_by_year.plot(kind='hist');

6. Lego Themes Over Years
Lego blocks ship under multiple themes. Let us try to get a sense of how the number of themes shipped has varied over the years.
themes_by_year = sets[['year', 'theme_id']].\
groupby('year', as_index=False).agg({'theme_id': pd.Series.nunique})
themes_by_year.head()