Up and Down With the Kardashians
While I'm not a fan nor a hater of the Kardashians and Jenners, the polarizing family intrigues me. Why? Their marketing prowess. Say what you will about them and what they stand for, they are great at the hype game. Everything they touch turns to content. In this Project, you will explore the data underneath the hype in the form of search interest data from Google Trends. You'll recreate the Google Trends plot to visualize their ups and downs over time, then make a few custom plots of your own. And you'll answer the big question - "is Kim even the most famous sister anymore?" This is the Result of Project "Up and Down With the Kardashians", via datacamp.




- 1. The sisters and Google Trends
- 2. Better "kolumn" names
- 3. Pesky data types
- 4. From object to integer
- 5. From object to datetime
- 6. Set month as index
- 7. The early Kim hype
- 8. Kylie's rise
- 9. Smooth out the fluctuations with rolling means
- 10. Who's more famous? The Kardashians or the Jenners?
1. The sisters and Google Trends
While I'm not a fan nor a hater of the Kardashians and Jenners, the polarizing family intrigues me. Why? Their marketing prowess. Say what you will about them and what they stand for, they are great at the hype game. Everything they touch turns to content.
The sisters in particular over the past decade have been especially productive in this regard. Let's get some facts straight. I consider the "sisters" to be the following daughters of Kris Jenner. Three from her first marriage to lawyer Robert Kardashian:
- Kourtney Kardashian (daughter of Robert Kardashian, born in 1979)
- Kim Kardashian (daughter of Robert Kardashian, born in 1980)
- Khloé Kardashian (daughter of Robert Kardashian, born in 1984)
And two from her second marriage to Olympic gold medal-winning decathlete, Caitlyn Jenner (formerly Bruce):
- Kendall Jenner (daughter of Caitlyn Jenner, born in 1995)
- Kylie Jenner (daughter of Caitlyn Jenner, born in 1997)
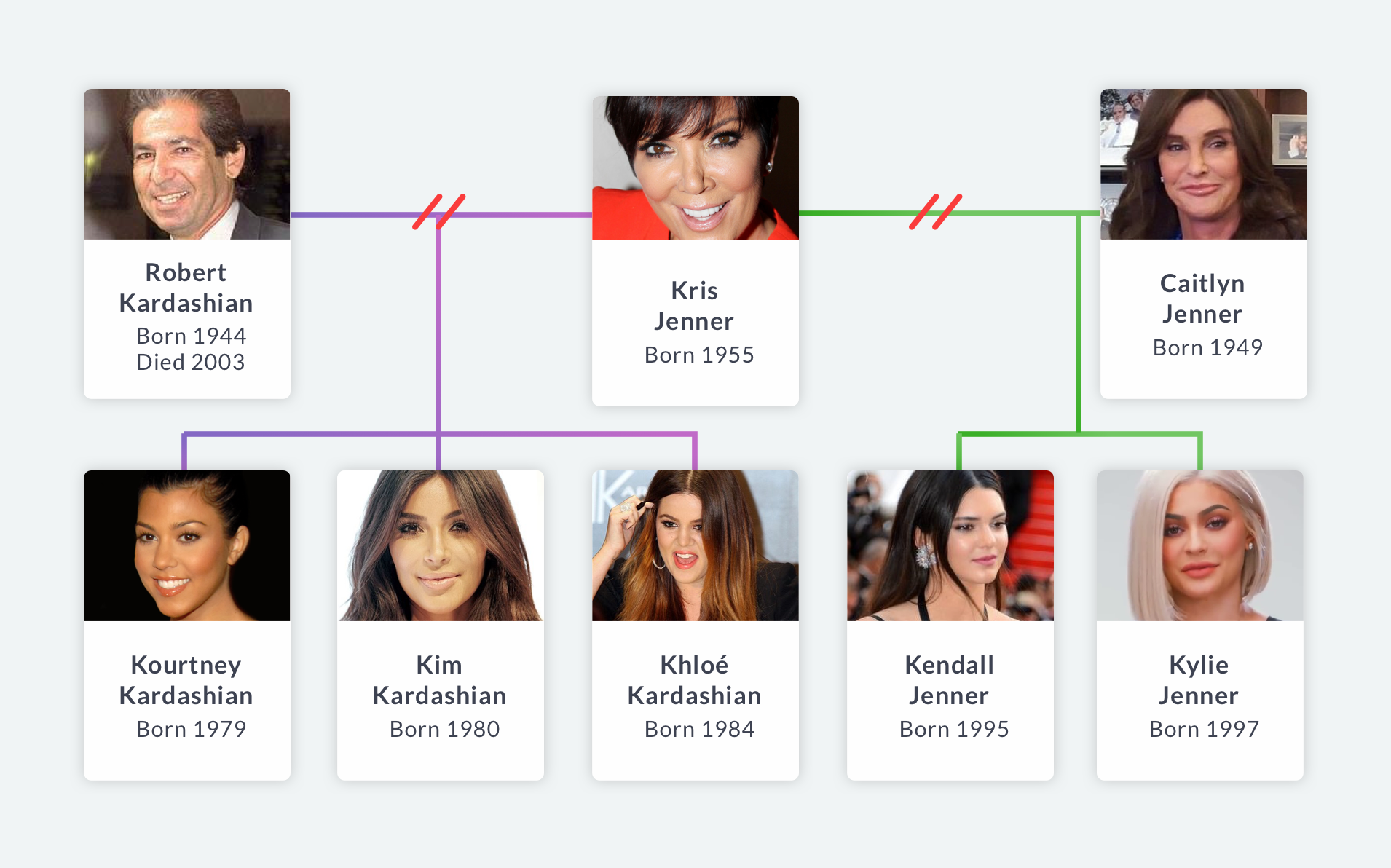
This family tree can be confusing, but we aren't here to explain it. We're here to explore the data underneath the hype, and we'll do it using search interest data from Google Trends. We'll recreate the Google Trends plot to visualize their ups and downs over time, then make a few custom plots of our own. And we'll answer the big question: is Kim even the most famous sister anymore?
First, let's load and inspect our Google Trends data, which was downloaded in CSV form. The query parameters: each of the sisters, worldwide search data, 2007 to present day. (2007 was the year Kim became "active" according to Wikipedia.)
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['figure.figsize'] = (10, 8)
trends = pd.read_csv('./dataset/trends_kj_sisters.csv')
# Inspect data
trends.head()
2. Better "kolumn" names
So we have a column for each month since January 2007 and a column for the worldwide search interest for each of the sisters each month. By the way, Google defines the values of search interest as:
Numbers represent search interest relative to the highest point on the chart for the given region and time. A value of 100 is the peak popularity for the term. A value of 50 means that the term is half as popular. A score of 0 means there was not enough data for this term.
Okay, that's great Google, but you are not making this data easily analyzable for us. I see a few things. Let's do the column names first. A column named "Kim Kardashian: (Worldwide)" is not the most usable for coding purposes. Let's shorten those so we can access their values better. Might as well standardize all column formats, too. I like lowercase, short column names.
trends.columns = ['month', 'kim', 'khloe', 'kourtney', 'kendall', 'kylie']
# Inspect data
trends.head()
3. Pesky data types
That's better. We don't need to scroll our eyes across the table to read the values anymore since it is much less wide. And seeing five columns that all start with the letter "k" … the aesthetics … we should call them "kolumns" now! (Bad joke.)
The next thing I see that is going to be an issue is that "<" sign. If "a score of 0 means there was not enough data for this term," "<1" must mean it is between 0 and 1 and Google does not want to give us the fraction from google.trends.com for whatever reason. That's fine, but this "<" sign means we won't be able to analyze or visualize our data right away because those column values aren't going to be represented as numbers in our data structure. Let's confirm that by inspecting our data types.
trends.info()
4. From object to integer
Yes, okay, the khloe, kourtney, and kendall columns aren't integers like the kim and kylie columns are. Again, because of the "<" sign that indicates a search interest value between zero and one. Is this an early hint at the hierarchy of sister popularity? We'll see shortly. Before that, we'll need to remove that pesky "<" sign. Then we can change the type of those columns to integer.
for column in trends.columns:
# Only modify columns that have the "<" sign
if "<" in trends[column].to_string():
# Remove "<" and convert dtype to integer
trends[column] = trends[column].str.replace("<", "")
trends[column] = pd.to_numeric(trends[column])
# Inspect data types and data
trends.info()
trends.head()
trends['month'] = pd.to_datetime(trends['month'])
# Inspect data types and data
trends.info()
trends.head()
trends = trends.set_index('month')
# Inspect the data
trends.head()
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 8))
trends.plot(ax=ax);

8. Kylie's rise
Oh my! There is so much to make sense of here. Kim's sharp rise in 2007, with the beginning of Keeping Up with the Kardashians, among other things. There was no significant search interest for the other four sisters until mid-2009 when Kourtney and Khloé launched the reality television series, Kourtney and Khloé Take Miami. Then there was Kim's rise from famous to literally more famous than God in 2011. This Cosmopolitan article covers the timeline that includes the launch of music videos, fragrances, iPhone and Android games, another television series, joining Instagram, and more. Then there was Kim's ridiculous spike in December 2014: posing naked on the cover of Paper Magazine in a bid to break the internet will do that for you.
A curious thing starts to happen after that bid as well. Let's zoom in…
fig, ax = plt.subplots(figsize=(10, 8))
trends.loc['2014-01':'2019-03'].plot(ax=ax);

9. Smooth out the fluctuations with rolling means
It looks like my suspicion may be true: Kim is not always the most searched Kardashian or Jenner sister. Since late-2016, at various months, Kylie overtakes Kim. Two big spikes where she smashed Kim's search interest: in September 2017 when it was reported that Kylie was expecting her first child with rapper Travis Scott and in February 2018 when she gave birth to her daughter, Stormi Webster. The continued success of Kylie Cosmetics has kept her in the news, not to mention making her the "The Youngest Self-Made Billionaire Ever" according to Forbes.
These fluctuations are descriptive but do not really help us answer our question: is Kim even the most famous sister anymore? We can use rolling means to smooth out short-term fluctuations in time series data and highlight long-term trends. Let's make the window twelve months a.k.a. one year.
fig, ax = plt.subplots(figsize=(10, 8))
trends.rolling(window=12).mean().plot(ax=ax);

10. Who's more famous? The Kardashians or the Jenners?
Whoa, okay! So by this metric, Kim is still the most famous sister despite Kylie being close and nearly taking her crown. Honestly, the biggest takeaway from this whole exercise might be Kendall not showing up that much. It makes sense, though, despite her wildly successful modeling career. Some have called her "the only normal one in her family" as she tends to shy away from the more dramatic and controversial parts of the media limelight that generate oh so many clicks.
Let's end this analysis with one last plot. In it, we will plot (pun!) the Kardashian sisters against the Jenner sisters to see which family line is more popular now. We will use average search interest to make things fair, i.e., total search interest divided by the number of sisters in the family line.
The answer? Since 2015, it has been a toss-up. And in the future? With this family and their penchant for big events, who knows?
trends['kardashian'] = trends[['kim', 'khloe', 'kourtney']].sum(axis=1) / 3
trends['jenner'] = trends[['kendall', 'kylie']].sum(axis=1) / 2
# Plot average family line search interest vs. month
fig, ax = plt.subplots(figsize=(10, 8))
trends[['kardashian', 'jenner']].plot(ax=ax);
