Kaggle competitions process
In this first chapter, you will get exposure to the Kaggle competition process. You will train a model and prepare a csv file ready for submission. You will learn the difference between Public and Private test splits, and how to prevent overfitting. This is the Summary of lecture "Winning a Kaggle Competition in Python", via datacamp.




import pandas as pd
import numpy as np
import matplotlib.pyplot as plt

Explore train data
You will work with another Kaggle competition called "Store Item Demand Forecasting Challenge". In this competition, you are given 5 years of store-item sales data, and asked to predict 3 months of sales for 50 different items in 10 different stores.
To begin, let's explore the train data for this competition. For the faster performance, you will work with a subset of the train data containing only a single month history.
Your initial goal is to read the input data and take the first look at it.
train = pd.read_csv('./dataset/demand_forecasting_train_1_month.csv')
# Look at the shape of the data
print('Train shape:', train.shape)
# Look at the head() of the data
train.head()
Explore test data
Having looked at the train data, let's explore the test data in the "Store Item Demand Forecasting Challenge". Remember, that the test dataset generally contains one column less than the train one.
This column, together with the output format, is presented in the sample submission file. Before making any progress in the competition, you should get familiar with the expected output.
That is why, let's look at the columns of the test dataset and compare it to the train columns. Additionally, let's explore the format of the sample submission.
test = pd.read_csv('./dataset/demand_forecasting_test.csv')
# Print train and test columns
print('Train columns:', train.columns.tolist())
print('Test columns:', test.columns.tolist())
sample_submission = pd.read_csv('./dataset/sample_submission.csv')
# Look at the head() of the sample submission
sample_submission.head()
The sample submission file consists of two columns: id of the observation and sales column for your predictions. Kaggle will evaluate your predictions on the true sales data for the corresponding id. So, it’s important to keep track of the predictions by id before submitting them.
Determine a problem type
You will keep working on the Store Item Demand Forecasting Challenge. Recall that you are given a history of store-item sales data, and asked to predict 3 months of the future sales.
Before building a model, you should determine the problem type you are addressing. The goal of this exercise is to look at the distribution of the target variable, and select the correct problem type you will be building a model for.
fig, ax = plt.subplots()
train.sales.hist(ax=ax);
ax.set_title('histogram of sales');

Train a simple model
As you determined, you are dealing with a regression problem. So, now you're ready to build a model for a subsequent submission. But now, instead of building the simplest Linear Regression model as in the slides, let's build an out-of-box Random Forest model.
You will use the RandomForestRegressor class from the scikit-learn library.
Your objective is to train a Random Forest model with default parameters on the "store" and "item" features.
from sklearn.ensemble import RandomForestRegressor
# Create a Random Forest object
rf = RandomForestRegressor()
# Train a model
rf.fit(X=train[['store', 'item']], y=train['sales'])
Prepare a submission
You've already built a model on the training data from the Kaggle Store Item Demand Forecasting Challenge. Now, it's time to make predictions on the test data and create a submission file in the specified format.
Your goal is to read the test data, make predictions, and save these in the format specified in the "sample_submission.csv" file.
sample_submission.head()
test['sales'] = rf.predict(test[['store', 'item']])
# Write test predictions using the sample_submission format
test[['id', 'sales']].to_csv('kaggle_submission.csv', index=False)
!head kaggle_submission.csv
Public vs Private leaderboard
- Competition metric
| Evaluation metric | Type of problem |
|---|---|
| Area Under the ROC (AUC) | Classification |
| F1 score (F1) | Classification |
| Mean Log Loss (LogLoss) | Classification |
| Mean Absolute Error (MAE) | Regression |
| Mean Squared Erro (MSE) | Regression |
| Mean Average Precision at K (MAPK, MAP@K) | Ranking |
- Overfitting in kaggle
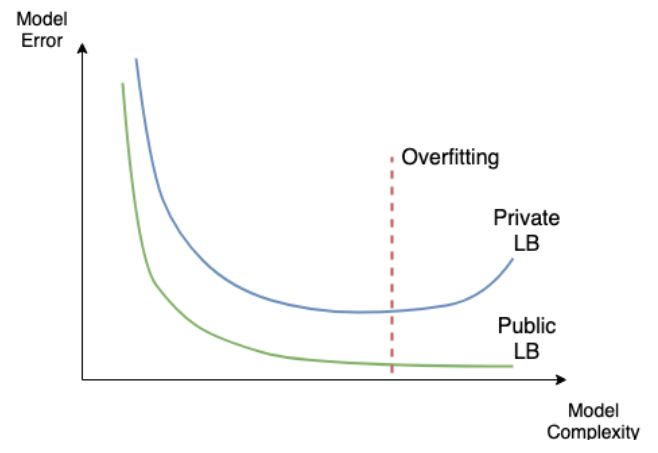
Train XGBoost models
Every Machine Learning method could potentially overfit. You will see it on this example with XGBoost. Again, you are working with the Store Item Demand Forecasting Challenge.
Firstly, let's train multiple XGBoost models with different sets of hyperparameters using XGBoost's learning API. The single hyperparameter you will change is:
-
max_depth- maximum depth of a tree. Increasing this value will make the model more complex and more likely to overfit.
import xgboost as xgb
# Create DMatrix on train data
dtrain = xgb.DMatrix(data=train[['store', 'item']],
label=train['sales'])
# Define xgboost parameters
params = {'objective': 'reg:squarederror',
'max_depth': 2,
'verbosity': 1}
# Train xgboost model
xg_depth_2 = xgb.train(params=params, dtrain=dtrain)
params = {'objective': 'reg:squarederror',
'max_depth': 8,
'verbosity': 1}
# Train xgboost model
xg_depth_8 = xgb.train(params=params, dtrain=dtrain)
params = {'objective': 'reg:squarederror',
'max_depth': 15,
'verbosity': 1}
# Train xgboost model
xg_depth_15 = xgb.train(params=params, dtrain=dtrain)
Explore overfitting XGBoost
Having trained 3 XGBoost models with different maximum depths, you will now evaluate their quality. For this purpose, you will measure the quality of each model on both the train data and the test data. As you know by now, the train data is the data models have been trained on. The test data is the next month sales data that models have never seen before.
The goal of this exercise is to determine whether any of the models trained is overfitting. To measure the quality of the models you will use Mean Squared Error (MSE). It's available in sklearn.metrics as mean_squared_error() function that takes two arguments: true values and predicted values.
from sklearn.metrics import mean_squared_error
dtrain = xgb.DMatrix(data=train[['store', 'item']])
dtest = xgb.DMatrix(data=test[['store', 'item']])
# For each of 3 trained models
for model in [xg_depth_2, xg_depth_8, xg_depth_15]:
# Make predictions
train_pred = model.predict(dtrain)
test_pred = model.predict(dtest)
# Calculate metrics
mse_train = mean_squared_error(train['sales'], train_pred)
mse_test = mean_squared_error(test['sales'], test_pred)
print('MSE Train: {:.3f}. MSE Test: {:.3f}'.format(mse_train, mse_test))