Bagging and Random Forests
A Summary of lecture "Machine Learning with Tree-Based Models in Python




import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Bagging
- Ensemble Methods
- Voting Classifier
- same training set,
- $\neq$ algortihms
- Bagging
- One algorithm
- $\neq$ subsets of the training set
- Voting Classifier
- Bagging
- Bootstrap Aggregation
- Uses a technique known as the bootstrap
- Reduces variance of individual models in the ensemble
_ Bootstrap
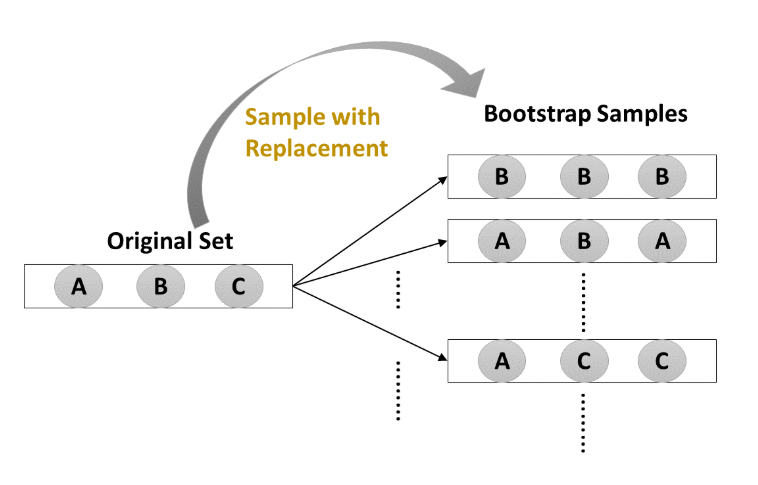
- Bootstrap-training
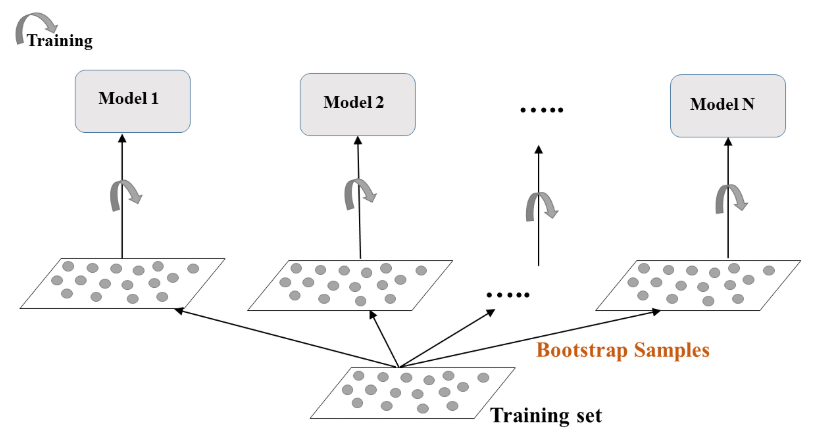
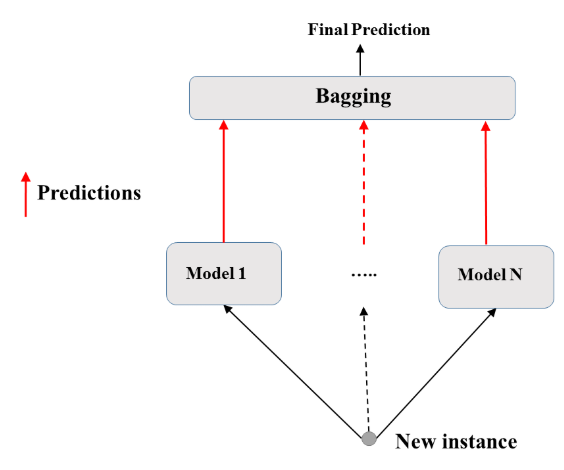
- Bootstrap-predict
Define the bagging classifier
In the following exercises you'll work with the Indian Liver Patient dataset from the UCI machine learning repository. Your task is to predict whether a patient suffers from a liver disease using 10 features including Albumin, age and gender. You'll do so using a Bagging Classifier.
- Preprocess
indian = pd.read_csv('./dataset/indian_liver_patient_preprocessed.csv', index_col=0)
indian.head()
X = indian.drop('Liver_disease', axis='columns')
y = indian['Liver_disease']
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
# Instantiate dt
dt = DecisionTreeClassifier(random_state=1)
# Instantiate bc
bc = BaggingClassifier(base_estimator=dt, n_estimators=50, random_state=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=1)
from sklearn.metrics import accuracy_score
# Fit bc to the training set
bc.fit(X_train, y_train)
# Predict test set labels
y_pred = bc.predict(X_test)
# Evaluate acc_test
acc_test = accuracy_score(y_test, y_pred)
print('Test set accuracy of bc: {:.2f}'.format(acc_test))
dt.fit(X_train, y_train)
y_pred_dt = dt.predict(X_test)
acc_test_dt = accuracy_score(y_test, y_pred_dt)
print('Test set accuracy of dt: {:.2f}'.format(acc_test_dt))
Prepare the ground
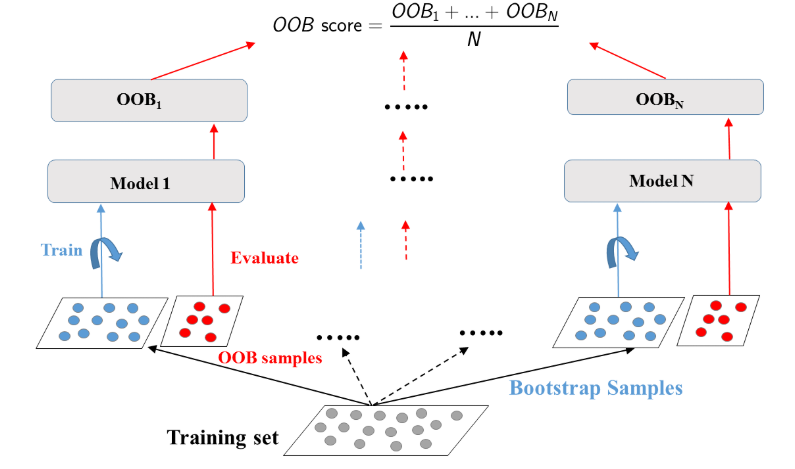
In the following exercises, you'll compare the OOB accuracy to the test set accuracy of a bagging classifier trained on the Indian Liver Patient dataset.
In sklearn, you can evaluate the OOB accuracy of an ensemble classifier by setting the parameter oob_score to True during instantiation. After training the classifier, the OOB accuracy can be obtained by accessing the .oob_score_ attribute from the corresponding instance.
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
# Instantiate dt
dt = DecisionTreeClassifier(min_samples_leaf=8, random_state=1)
# Instantiate bc
bc = BaggingClassifier(base_estimator=dt, n_estimators=50, oob_score=True, random_state=1)
bc.fit(X_train, y_train)
# Predict test set labels
y_pred = bc.predict(X_test)
# Evaluate test set accuracy
acc_test = accuracy_score(y_test, y_pred)
# Evaluate OOB accuracy
acc_oob = bc.oob_score_
# Print acc_test and acc_oob
print('Test set accuracy: {:.3f}, OOB accuracy: {:.3f}'.format(acc_test, acc_oob))
Random Forests (RF)
- Bagging
- Base estimator: Decision Tree, Logistic Regression, Neural Network, ...
- Each estimator is trained on a distinct bootstrap sample of the training set
- Estimators use all features for training and prediction
- Further Diversity with Random Forest
- Base estimator: Decision Tree
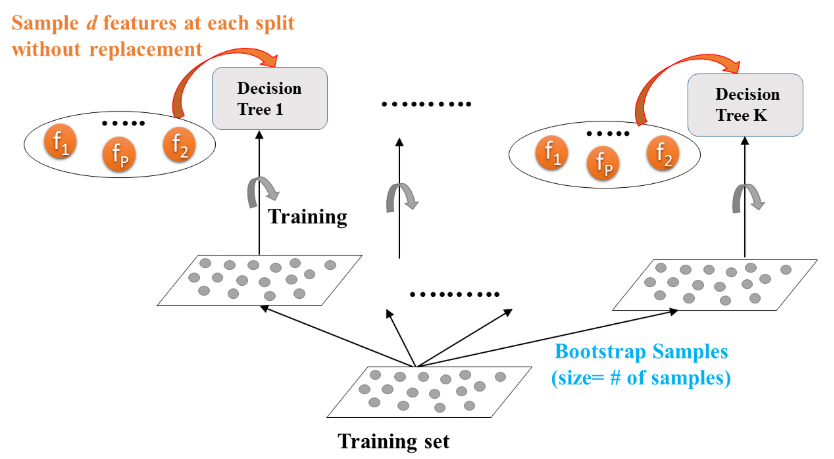
- Each estimator is trained on a different bootstrap sample having the same size as the training set
- RF introduces further randomization in the training of individual trees
- $d$ features are sampled at each node without replacement $$ d < \text{total number of features} $$
- Random Forest: Training
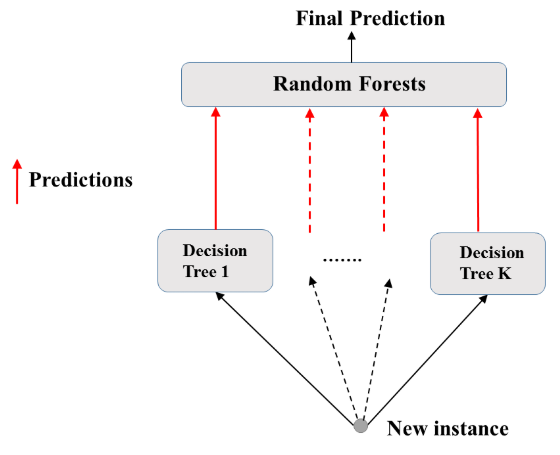
- Random Forest: Prediction
- Feature importance
- Tree based methods: enable measuring the importance of each feature in prediction
Train an RF regressor
In the following exercises you'll predict bike rental demand in the Capital Bikeshare program in Washington, D.C using historical weather data from the Bike Sharing Demand dataset available through Kaggle. For this purpose, you will be using the random forests algorithm. As a first step, you'll define a random forests regressor and fit it to the training set.
- Preprocess
bike = pd.read_csv('./dataset/bikes.csv')
bike.head()
X = bike.drop('cnt', axis='columns')
y = bike['cnt']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2)
from sklearn.ensemble import RandomForestRegressor
# Instantiate rf
rf = RandomForestRegressor(n_estimators=25, random_state=2)
# Fit rf to the training set
rf.fit(X_train, y_train)
from sklearn.metrics import mean_squared_error as MSE
# Predict the test set labels
y_pred = rf.predict(X_test)
# Evaluate the test set RMSE
rmse_test = MSE(y_test, y_pred) ** 0.5
# Print rmse_test
print('Test set RMSE of rf: {:.2f}'.format(rmse_test))
Visualizing features importances
In this exercise, you'll determine which features were the most predictive according to the random forests regressor rf that you trained in a previous exercise.
For this purpose, you'll draw a horizontal barplot of the feature importance as assessed by rf. Fortunately, this can be done easily thanks to plotting capabilities of pandas.
importances = pd.Series(data=rf.feature_importances_, index=X_train.columns)
# Sort importances
importances_sorted = importances.sort_values()
# Draw a horizontal barplot of importances_sorted
importances_sorted.plot(kind='barh', color='lightgreen')
plt.title('Features Importances')
plt.savefig('../images/feature_importances.png')

Apparently, hr and workingday are the most important features according to rf. The importances of these two features add up to more than 90%!