K-Means Clustering
A Summary of lecture "Cluster Analysis in Python", via datacamp




import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
K-means clustering: first exercise
This exercise will familiarize you with the usage of k-means clustering on a dataset. Let us use the Comic Con dataset and check how k-means clustering works on it.
Recall the two steps of k-means clustering:
- Define cluster centers through
kmeans()function. It has two required arguments: observations and number of clusters. - Assign cluster labels through the
vq()function. It has two required arguments: observations and cluster centers.
- Preprocess
comic_con = pd.read_csv('./dataset/comic_con.csv', index_col=0)
comic_con.head()
from scipy.cluster.vq import whiten
comic_con['x_scaled'] = whiten(comic_con['x_coordinate'])
comic_con['y_scaled'] = whiten(comic_con['y_coordinate'])
from scipy.cluster.vq import kmeans, vq
# Generate cluster centers
cluster_centers, distortions = kmeans(comic_con[['x_scaled', 'y_scaled']], 2)
# Assign cluster labels
comic_con['cluster_labels'], distortion_list = vq(comic_con[['x_scaled', 'y_scaled']], cluster_centers)
# Plot clusters
sns.scatterplot(x='x_scaled', y='y_scaled', hue='cluster_labels', data=comic_con);

- Preprocess
fifa = pd.read_csv('./dataset/fifa_18_dataset.csv')
fifa.head()
fifa['scaled_sliding_tackle'] = whiten(fifa['sliding_tackle'])
fifa['scaled_aggression'] = whiten(fifa['aggression'])
from scipy.cluster.hierarchy import linkage
%timeit linkage(fifa[['scaled_sliding_tackle', 'scaled_aggression']], method='ward')
%timeit kmeans(fifa[['scaled_sliding_tackle', 'scaled_aggression']], 2)
How many clusters?
- How to find the right k?
- No absolute method to find right number of clusters(k) in k-means clustering
- Elbow method
- Distortion
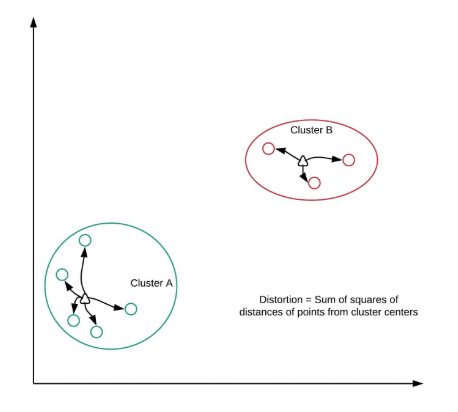
- sum of squared distances of points from cluster centers
- Decreases with an increasing number of clusters
- Becomes zero when the number of clusters equals the numbers of points
- Elbow plot: line plot between cluster centers and distortion
- Elbow method
- Elbow plot helps indicate number of clusters present in data
- Only gives an indication of optimal k
- Does not always pinpoint how many k
- Other methods : average silhouette, gap statistic
distortions = []
num_clusters = range(1, 7)
# Create a list of distortions from the kmeans function
for i in num_clusters:
cluster_centers, distortion = kmeans(comic_con[['x_scaled', 'y_scaled']], i)
distortions.append(distortion)
# Create a data frame with two lists - num_clusters, distortions
elbow_plot = pd.DataFrame({'num_clusters': num_clusters, 'distortions': distortions})
# Create a line plot of num_clusters and distortions
sns.lineplot(x='num_clusters', y='distortions', data=elbow_plot);
plt.xticks(num_clusters);

Elbow method on uniform data
In the earlier exercise, you constructed an elbow plot on data with well-defined clusters. Let us now see how the elbow plot looks on a data set with uniformly distributed points. You may want to display the data points on the console before proceeding with the exercise.
- Preprocess
uniform_data = pd.read_csv('./dataset/uniform_data.csv', index_col=0)
uniform_data.head()
uniform_data['x_scaled'] = whiten(uniform_data['x_coordinate'])
uniform_data['y_scaled'] = whiten(uniform_data['y_coordinate'])
distortions = []
num_clusters = range(2, 7)
# Create a list of distortions from the kmeans function
for i in num_clusters:
cluster_centers, distortion = kmeans(uniform_data[['x_scaled', 'y_scaled']], i)
distortions.append(distortion)
# Create a data frame with two lists - num_clusters, distortions
elbow_plot = pd.DataFrame({'num_clusters': num_clusters, 'distortions': distortions})
# Create a line plot of num_clusters and distortions
sns.lineplot(x='num_clusters', y='distortions', data=elbow_plot);
plt.xticks(num_clusters);

np.random.seed(0)
# Run kmeans clustering
cluster_centers, distortion = kmeans(comic_con[['x_scaled', 'y_scaled']], 2)
comic_con['cluster_labels'], distortion_list = vq(comic_con[['x_scaled', 'y_scaled']], cluster_centers)
# Plot the scatterplot
sns.scatterplot(x='x_scaled', y='y_scaled', hue='cluster_labels', data=comic_con);

np.random.seed([1, 2, 1000])
# Run kmeans clustering
cluster_centers, distortion = kmeans(comic_con[['x_scaled', 'y_scaled']], 2)
comic_con['cluster_labels'], distortion_list = vq(comic_con[['x_scaled', 'y_scaled']], cluster_centers)
# Plot the scatterplot
sns.scatterplot(x='x_scaled', y='y_scaled', hue='cluster_labels', data=comic_con);
Uniform clustering patterns
Now that you are familiar with the impact of seeds, let us look at the bias in k-means clustering towards the formation of uniform clusters.
Let us use a mouse-like dataset for our next exercise. A mouse-like dataset is a group of points that resemble the head of a mouse: it has three clusters of points arranged in circles, one each for the face and two ears of a mouse.
- preprocess
mouse = pd.read_csv('./dataset/mouse.csv', index_col=0)
mouse.head()
mouse['x_scaled'] = whiten(mouse['x_coordinate'])
mouse['y_scaled'] = whiten(mouse['y_coordinate'])
cluster_centers, distortion = kmeans(mouse[['x_scaled', 'y_scaled']], 3)
# Assign cluster labels
mouse['cluster_labels'], distortion_list = vq(mouse[['x_scaled', 'y_scaled']], cluster_centers)
# Plot clusters
sns.scatterplot(x='x_scaled', y='y_scaled', hue='cluster_labels', data=mouse);

FIFA 18: defenders revisited
In the FIFA 18 dataset, various attributes of players are present. Two such attributes are:
- defending: a number which signifies the defending attributes of a player
- physical: a number which signifies the physical attributes of a player
These are typically defense-minded players. In this exercise, you will perform clustering based on these attributes in the data.
- Preprocess
fifa = pd.read_csv('./dataset/fifa_18_sample_data.csv')
fifa.head()
fifa = fifa[['def', 'phy']].copy()
fifa['scaled_def'] = whiten(fifa['def'])
fifa['scaled_phy'] = whiten(fifa['phy'])
np.random.seed([1000, 2000])
# Fit the data into a k-means algorithm
cluster_centers, _ = kmeans(fifa[['scaled_def', 'scaled_phy']], 3)
# Assign cluster labels
fifa['cluster_labels'], _ = vq(fifa[['scaled_def', 'scaled_phy']], cluster_centers)
# Display cluster centers
print(fifa[['scaled_def', 'scaled_phy', 'cluster_labels']].groupby('cluster_labels').mean())
# Create a scatter plot through seaborn
sns.scatterplot(x='scaled_def', y='scaled_phy', hue='cluster_labels', data=fifa);
