Regression in PySpark
Next you'll learn to create Linear Regression models. You'll also find out how to augment your data by engineering new predictors as well as a robust approach to selecting only the most relevant predictors. This is the Summary of lecture "Machine Learning with PySpark", via datacamp.




import pyspark
from pyspark.sql import SparkSession
import numpy as np
import pandas as pd
Encoding flight origin
The org column in the flights data is a categorical variable giving the airport from which a flight departs.
- ORD — O'Hare International Airport (Chicago)
- SFO — San Francisco International Airport
- JFK — John F Kennedy International Airport (New York)
- LGA — La Guardia Airport (New York)
- SMF — Sacramento
- SJC — San Jose
- TUS — Tucson International Airport
- OGG — Kahului (Hawaii)
Obviously this is only a small subset of airports. Nevertheless, since this is a categorical variable, it needs to be one-hot encoded before it can be used in a regression model.
spark = SparkSession.builder.master('local[*]').appName('flights').getOrCreate()
# Read data from CSV file
flights = spark.read.csv('./dataset/flights-larger.csv', sep=',', header=True, inferSchema=True,
nullValue='NA')
# Get number of records
print("The data contain %d records." % flights.count())
# View the first five records
flights.show(5)
# Check column data types
print(flights.printSchema())
print(flights.dtypes)
from pyspark.ml.feature import StringIndexer
flights = StringIndexer(inputCol='org', outputCol='org_idx').fit(flights).transform(flights)
flights.show()
OneHotEncoderEstimator is replaced with OneHotEncoder in 3.0.0
from pyspark.ml.feature import OneHotEncoder
# Create an instance of the one hot encoder
onehot = OneHotEncoder(inputCols=['org_idx'], outputCols=['org_dummy'])
# Apply the one hot encoder to the flights data
onehot = onehot.fit(flights)
flights_onehot = onehot.transform(flights)
# Check the results
flights_onehot.select('org', 'org_idx', 'org_dummy').distinct().sort('org_idx').show()
flights_onehot.show(5)
from pyspark.sql.functions import round
# Convert 'mile' to 'km' and drop 'mile' column
flights_onehot = flights_onehot.withColumn('km', round(flights_onehot.mile * 1.60934, 0)).drop('mile')
flights_onehot.show(5)
from pyspark.ml.feature import VectorAssembler
# Create an assembler object
assembler = VectorAssembler(inputCols=['km'], outputCol='features')
# Consolidate predictor columns
flights = assembler.transform(flights_onehot)
flights.show(5)
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
# Create a regression object and train on training data
regression = LinearRegression(featuresCol='features', labelCol='duration').fit(flights_train)
# Create predictions for the test data and take a look at the predictions
predictions = regression.transform(flights_test)
predictions.select('duration', 'prediction').show(5, False)
# Calculate the RMSE
RegressionEvaluator(labelCol='duration', metricName='rmse').evaluate(predictions)
Interpreting the coefficients
The linear regression model for flight duration as a function of distance takes the form
duration = $\alpha$ + $\beta$ × distance
where
- $\alpha$ — intercept (component of duration which does not depend on distance) and
- $\beta$ — coefficient (rate at which duration increases as a function of distance; also called the slope).
By looking at the coefficients of your model you will be able to infer
- how much of the average flight duration is actually spent on the ground and
- what the average speed is during a flight.
inter = regression.intercept
print(inter)
# Coefficients
coefs = regression.coefficients
print(coefs)
# Average minutes per km
minutes_per_km = regression.coefficients[0]
print(minutes_per_km)
# Average speed in km per hour
avg_speed = 60 / minutes_per_km
print(avg_speed)
Flight duration model - Adding origin airport
Some airports are busier than others. Some airports are bigger than others too. Flights departing from large or busy airports are likely to spend more time taxiing or waiting for their takeoff slot. So it stands to reason that the duration of a flight might depend not only on the distance being covered but also the airport from which the flight departs.
You are going to make the regression model a little more sophisticated by including the departure airport as a predictor.
assembler = VectorAssembler(inputCols=['km', 'org_dummy'], outputCol='features')
# Consolidate predictor columns
flights = assembler.transform(flights_onehot)
flights.show(5)
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Create a regression object and train on training data
regression = LinearRegression(featuresCol='features', labelCol='duration').fit(flights_train)
# Create predictions for the test data
predictions = regression.transform(flights_test)
# Calculate the RMSE on test data
RegressionEvaluator(labelCol='duration', metricName='rmse').evaluate(predictions)
Interpreting coefficients
Remember that origin airport, org, has eight possible values (ORD, SFO, JFK, LGA, SMF, SJC, TUS and OGG) which have been one-hot encoded to seven dummy variables in org_dummy.
The values for km and org_dummy have been assembled into features, which has eight columns with sparse representation. Column indices in features are as follows:
- 0 —
km - 1 —
ORD - 2 —
SFO - 3 —
JFK - 4 —
LGA - 5 —
SMF - 6 —
SJCand - 7 —
TUS. Note thatOGGdoes not appear in this list because it is the reference level for the origin airport category.
In this exercise you'll be using the intercept and coefficients attributes to interpret the model.
The coefficients attribute is a list, where the first element indicates how flight duration changes with flight distance.
avg_speed_hour = 60 / regression.coefficients[0]
print(avg_speed_hour)
# Averate minutes on ground at OGG
inter = regression.intercept
print(inter)
# Average minutes on ground at JFK
avg_ground_jfk= inter + regression.coefficients[3]
print(avg_ground_jfk)
# Average minutes on ground at LGA
avg_ground_lga = inter + regression.coefficients[4]
print(avg_ground_lga)
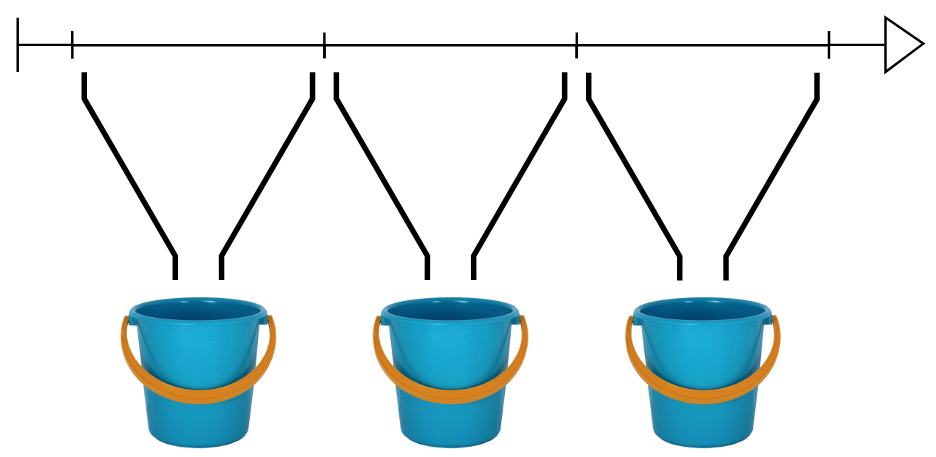
Bucketing departure time
Time of day data are a challenge with regression models. They are also a great candidate for bucketing.
In this lesson you will convert the flight departure times from numeric values between 0 (corresponding to "00:00") and 24 (corresponding to "24:00") to binned values. You'll then take those binned values and one-hot encode them.
from pyspark.ml.feature import Bucketizer
# Create buckets at 3 hour intervals through the day
buckets = Bucketizer(splits=[
3 * x for x in range(9)
], inputCol='depart', outputCol='depart_bucket')
# Bucket the departure times
bucketed = buckets.transform(flights)
bucketed.select('depart', 'depart_bucket').show(5)
# Create a one-hot encoder
onehot = OneHotEncoder(inputCols=['depart_bucket'], outputCols=['depart_dummy'])
# One-hot encode the bucketed departure times
flights_onehot = onehot.fit(bucketed).transform(bucketed)
flights_onehot.select('depart', 'depart_bucket', 'depart_dummy').show(5)
Flight duration model - Adding departure time
In the previous exercise the departure time was bucketed and converted to dummy variables. Now you're going to include those dummy variables in a regression model for flight duration.
The data are in flights. The km, org_dummy and depart_dummy columns have been assembled into features, where km is index 0, org_dummy runs from index 1 to 7 and depart_dummy from index 8 to 14.
assembler = VectorAssembler(inputCols=['km', 'org_dummy', 'depart_dummy'], outputCol='features')
flights = assembler.transform(flights_onehot.drop('features'))
flights.show(5)
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Train with training data
regression = LinearRegression(labelCol='duration').fit(flights_train)
predictions = regression.transform(flights_test)
RegressionEvaluator(labelCol='duration', metricName='rmse').evaluate(predictions)
# Average minutes on ground at OGG for flights departing between 21:00 and 24:00
avg_eve_ogg = regression.intercept
print(avg_eve_ogg)
# Average minutes on ground at OGG for flights departing between 00:00 and 03:00
avg_night_ogg = regression.intercept + regression.coefficients[8]
print(avg_night_ogg)
# Average minutes on ground at JFK for flights departing between 00:00 and 03:00
avg_night_jfk = regression.intercept + regression.coefficients[3] + regression.coefficients[8]
print(avg_night_jfk)
Regularization
- Feature Selection
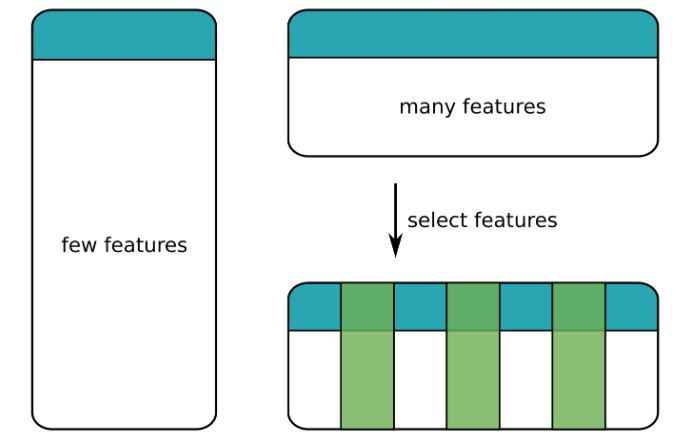
- Loss function
- Linear regression aims to minimize the MSE $$ MSE = \frac{1}{N} \sum_{i=1}^{N}(y_i - \hat{y_i})^2 $$
- Loss function with regularization
- Add a regularization term which depends on coefficients $$ MSE = \frac{1}{N} \sum_{i=1}^{N}(y_i - \hat{y_i})^2 + \lambda f(\beta) $$
- Regularizer
- Lasso - absolute value of the coefficients
- Ridge - square of the coefficients
- Both will shrink the coefficients of unimportant predictors
- Strength of regularization determined by parameter $\lambda$:
- $\lambda = 0$ - no regularization (standard regression)
- $\lambda = \infty$ - complete regularization (all coefficients zero)
Flight duration model - More features!
Let's add more features to our model. This will not necessarily result in a better model. Adding some features might improve the model. Adding other features might make it worse.
More features will always make the model more complicated and difficult to interpret.
These are the features you'll include in the next model:
km-
org(origin airport, one-hot encoded, 8 levels) -
depart(departure time, binned in 3 hour intervals, one-hot encoded, 8 levels) -
dow(departure day of week, one-hot encoded, 7 levels) and -
mon(departure month, one-hot encoded, 12 levels).
These have been assembled into the features column, which is a sparse representation of 32 columns (remember one-hot encoding produces a number of columns which is one fewer than the number of levels).
onehot = OneHotEncoder(inputCols=['dow'], outputCols=['dow_dummy'])
flights = onehot.fit(flights).transform(flights)
onehot = OneHotEncoder(inputCols=['mon'], outputCols=['mon_dummy'])
flights = onehot.fit(flights).transform(flights)
flights.show(5)
assembler = VectorAssembler(inputCols=[
'km', 'org_dummy', 'depart_dummy', 'dow_dummy', 'mon_dummy'
], outputCol='features')
flights = assembler.transform(flights.drop('features'))
flights.show(5)
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Fit linear regressino model to training data
regression = LinearRegression(labelCol='duration').fit(flights_train)
# Make predictions on test data
predictions = regression.transform(flights_test)
# Calculate the RMSE on test data
rmse = RegressionEvaluator(labelCol='duration', metricName='rmse').evaluate(predictions)
print("The test RMSE is", rmse)
# Look at the model coefficients
coeffs = regression.coefficients
print(coeffs)
Flight duration model - Regularization!
In the previous exercise you added more predictors to the flight duration model. The model performed well on testing data, but with so many coefficients it was difficult to interpret.
In this exercise you'll use Lasso regression (regularized with a L1 penalty) to create a more parsimonious model. Many of the coefficients in the resulting model will be set to zero. This means that only a subset of the predictors actually contribute to the model. Despite the simpler model, it still produces a good RMSE on the testing data.
You'll use a specific value for the regularization strength. Later you'll learn how to find the best value using cross validation.
regression = LinearRegression(labelCol='duration', regParam=1, elasticNetParam=1).fit(flights_train)
predictions = regression.transform(flights_test)
# Calculate the RMSE on testing data
rmse = RegressionEvaluator(labelCol='duration', metricName='rmse').evaluate(predictions)
print("The test RMSE is", rmse)
# Look at the model coefficients
coeffs = regression.coefficients
print(coeffs)
# Number of zero coefficients
zero_coeff = sum([beta == 0 for beta in regression.coefficients])
print("Number of coefficients equal to 0:", zero_coeff)