Machine Learning with PySpark - Introduction
Spark is a framework for working with Big Data. In this chapter you'll cover some background about Spark and Machine Learning. You'll then find out how to connect to Spark using Python and load CSV data.




import pyspark
import numpy as np
import pandas as pd
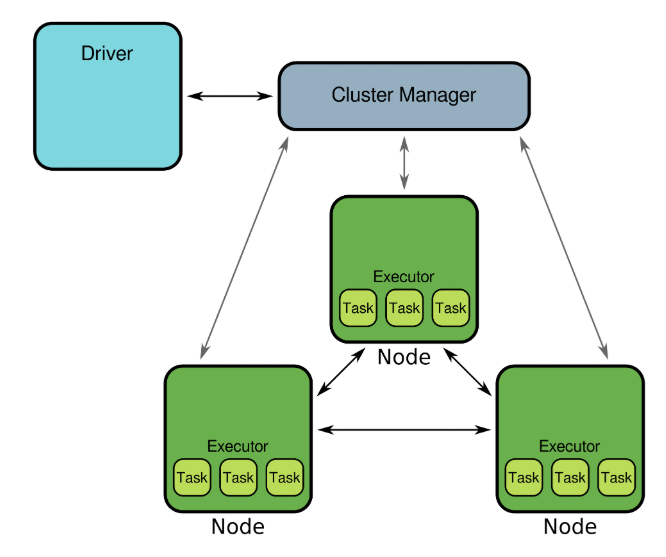
Creating a SparkSession
In this exercise, you'll spin up a local Spark cluster using all available cores. The cluster will be accessible via a SparkSession object.
The SparkSession class has a builder attribute, which is an instance of the Builder class. The Builder class exposes three important methods that let you:
- specify the location of the master node;
- name the application (optional); and
- retrieve an existing
SparkSessionor, if there is none, create a new one.
The SparkSession class has a version attribute which gives the version of Spark.
Find out more about SparkSession here.
Once you are finished with the cluster, it's a good idea to shut it down, which will free up its resources, making them available for other processes.
from pyspark.sql import SparkSession
# Create SparkSession object
spark = SparkSession.builder.master('local[*]').appName('test').getOrCreate()
# What version of Spark?
print(spark.version)
# Terminate the cluster
spark.stop()
Loading flights data
In this exercise you're going to load some airline flight data from a CSV file. To ensure that the exercise runs quickly these data have been trimmed down to only 50 000 records. You can get a larger dataset in the same format here.
Notes on CSV format:
- fields are separated by a comma (this is the default separator) and
- missing data are denoted by the string 'NA'.
Data dictionary:
-
mon— month (integer between 1 and 12) -
dom— day of month (integer between 1 and 31) -
dow— day of week (integer; 1 = Monday and 7 = Sunday) -
org— origin airport (IATA code) -
mile— distance (miles) -
carrier— carrier (IATA code) -
depart— departure time (decimal hour) -
duration— expected duration (minutes) -
delay— delay (minutes)
spark = SparkSession.builder.master('local[*]').appName('flights').getOrCreate()
# Read data from CSV file
flights = spark.read.csv('./dataset/flights-larger.csv', sep=',', header=True, inferSchema=True,
nullValue='NA')
# Get number of records
print("The data contain %d records." % flights.count())
# View the first five records
flights.show(5)
# Check column data types
print(flights.printSchema())
print(flights.dtypes)
Loading SMS spam data
You've seen that it's possible to infer data types directly from the data. Sometimes it's convenient to have direct control over the column types. You do this by defining an explicit schema.
The file sms.csv contains a selection of SMS messages which have been classified as either 'spam' or 'ham'. These data have been adapted from the UCI Machine Learning Repository. There are a total of 5574 SMS, of which 747 have been labelled as spam.
Notes on CSV format:
- no header record and
- fields are separated by a semicolon (this is not the default separator).
Data dictionary:
-
id— record identifier -
text— content of SMS message -
label— spam or ham (integer; 0 = ham and 1 = spam)
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Specify column names and types
schema = StructType([
StructField("id", IntegerType()),
StructField("text", StringType()),
StructField("label", IntegerType())
])
# Load data from a delimited file
sms = spark.read.csv('./dataset/sms.csv', sep=';', header=False, schema=schema)
# Print schema of DataFrame
sms.printSchema()