Ensembles and Pipelines in PySpark
Finally you'll learn how to make your models more efficient. You'll find out how to use pipelines to make your code clearer and easier to maintain. Then you'll use cross-validation to better test your models and select good model parameters. Finally you'll dabble in two types of ensemble model. This is the Summary of lecture "Machine Learning with PySpark", via datacamp.




import pyspark
from pyspark.sql import SparkSession
import pandas as pd
import numpy as np
spark = SparkSession.builder.master('local[*]').appName('flights').getOrCreate()
# Read data from CSV file
flights = spark.read.csv('./dataset/flights-larger.csv', sep=',', header=True, inferSchema=True,
nullValue='NA')
# Get number of records
print("The data contain %d records." % flights.count())
# View the first five records
flights.show(5)
# Check column data types
print(flights.printSchema())
print(flights.dtypes)
from pyspark.sql.functions import round
# Convert 'mile' to 'km' and drop 'mile' column
flights = flights.withColumn('km', round(flights.mile * 1.60934, 0)).drop('mile')
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
from pyspark.ml.regression import LinearRegression
# Convert categorical strings to index values
indexer = StringIndexer(inputCol='org', outputCol='org_idx')
# One-hot encode index values
onehot = OneHotEncoder(
inputCols=['org_idx', 'dow'],
outputCols=['org_dummy', 'dow_dummy']
)
# Assemble predictors into a single column
assembler = VectorAssembler(inputCols=['km', 'org_dummy', 'dow_dummy'], outputCol='features')
# A linear regression object
regression = LinearRegression(labelCol='duration')
Flight duration model: Pipeline model
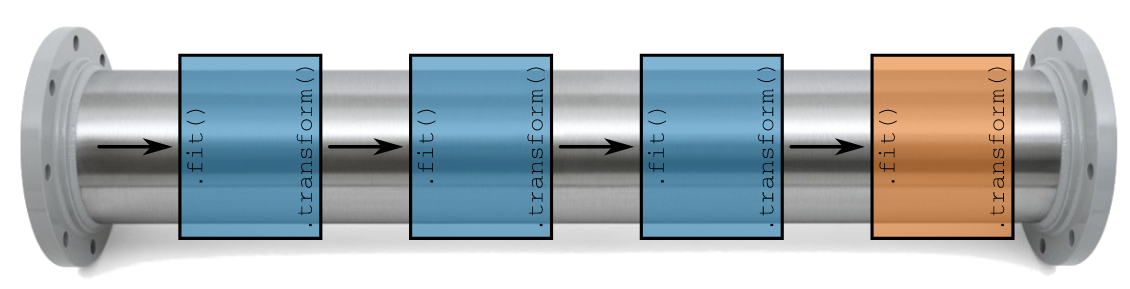
You're now ready to put those stages together in a pipeline.
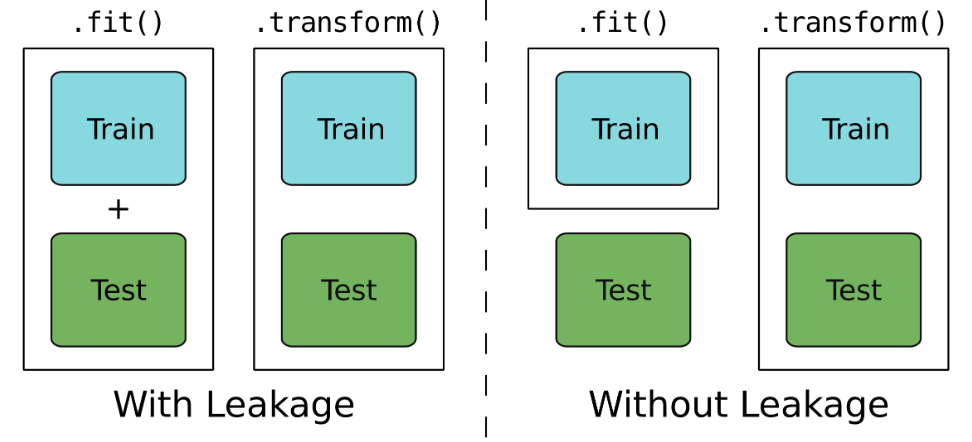
You'll construct the pipeline and then train the pipeline on the training data. This will apply each of the individual stages in the pipeline to the training data in turn. None of the stages will be exposed to the testing data at all: there will be no leakage!
Once the entire pipeline has been trained it will then be used to make predictions on the testing data.
from pyspark.ml import Pipeline
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Construct a pipeline
pipeline = Pipeline(stages=[indexer, onehot, assembler, regression])
# Train the pipeline on the training data
pipeline = pipeline.fit(flights_train)
# Make predictions on the test data
predictions = pipeline.transform(flights_test)
SMS spam pipeline
You haven't looked at the SMS data for quite a while. Last time we did the following:
- split the text into tokens
- removed stop words
- applied the hashing trick
- converted the data from counts to IDF and
- trained a linear regression model.
Each of these steps was done independently. This seems like a great application for a pipeline!
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Specify column names and types
schema = StructType([
StructField("id", IntegerType()),
StructField("text", StringType()),
StructField("label", IntegerType())
])
# Read data from CSV file
sms = spark.read.csv('./dataset/sms.csv', sep=';', header=False, schema=schema, nullValue='NA')
sms.show(5)
from pyspark.ml.feature import Tokenizer, StopWordsRemover, HashingTF, IDF
from pyspark.ml.classification import LogisticRegression
# Break text into tokens at non-word characters
tokenizer = Tokenizer(inputCol='text', outputCol='words')
# Remove stop words
remover = StopWordsRemover(inputCol=tokenizer.getOutputCol(), outputCol='terms')
# Apply the hashing trick and transform to TF-IDF
hasher = HashingTF(inputCol=remover.getOutputCol(), outputCol='hash')
idf = IDF(inputCol=hasher.getOutputCol(), outputCol='features')
# Create a logistic regression object and add everything to a pipeline
logistic = LogisticRegression()
pipeline = Pipeline(stages=[tokenizer, remover, hasher, idf, logistic])
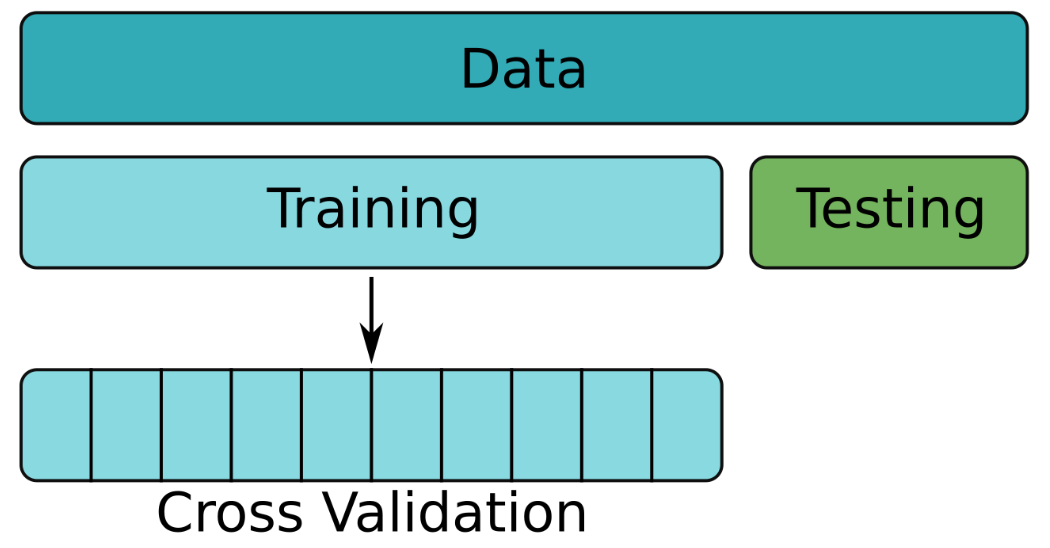
Cross validating simple flight duration model
You've already built a few models for predicting flight duration and evaluated them with a simple train/test split. However, cross-validation provides a much better way to evaluate model performance.
In this exercise you're going to train a simple model for flight duration using cross-validation. Travel time is usually strongly correlated with distance, so using the km column alone should give a decent model.
assembler = VectorAssembler(inputCols=['km'], outputCol='features')
flights = assembler.transform(flights.drop('features'))
flights.show(5)
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
from pyspark.ml.evaluation import RegressionEvaluator
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Create an empty parameter grid
params = ParamGridBuilder().build()
# Create objects for building and evaluating a regression model
regression = LinearRegression(labelCol='duration')
evaluator = RegressionEvaluator(labelCol='duration')
# Create a cross validator
cv = CrossValidator(estimator=regression, estimatorParamMaps=params,
evaluator=evaluator, numFolds=5)
# Train and test model on multiple folds of the training data
cv = cv.fit(flights_train)
Cross validating flight duration model pipeline
The cross-validated model that you just built was simple, using km alone to predict duration.
Another important predictor of flight duration is the origin airport. Flights generally take longer to get into the air from busy airports. Let's see if adding this predictor improves the model!
In this exercise you'll add the org field to the model. However, since org is categorical, there's more work to be done before it can be included: it must first be transformed to an index and then one-hot encoded before being assembled with km and used to build the regression model. We'll wrap these operations up in a pipeline.
params = ParamGridBuilder().build()
# Create regression model
regression = LinearRegression(labelCol='duration')
evaluator = RegressionEvaluator(labelCol='duration')
# Create an indexer for the org field
indexer = StringIndexer(inputCol='org', outputCol='org_idx')
# Create an one-hot encoder for the indexed org field
onehot = OneHotEncoder(inputCol='org_idx', outputCol='org_dummy')
# Assemble the km and one-hot encoded fields
assembler = VectorAssembler(inputCols=['km', 'org_dummy'], outputCol='features')
# Create a pipeline and cross-validator
pipeline = Pipeline(stages=[indexer, onehot, assembler, regression])
cv = CrossValidator(estimator=pipeline,
estimatorParamMaps=params,
evaluator=evaluator)
params = ParamGridBuilder()
# Add grids for two parameters
params = params.addGrid(regression.regParam, [0.01, 0.1, 1.0, 10.0])\
.addGrid(regression.elasticNetParam, [0.0, 0.5, 1.0])
# Build the parameter grid
params = params.build()
print('Number of models to be tested: ', len(params))
# Create cross-validator
cv = CrossValidator(estimator=pipeline, estimatorParamMaps=params,
evaluator=evaluator, numFolds=5)
flights_train, flights_test = flights.drop('features').randomSplit([0.8, 0.2])
# Train the data
cvModel = cv.fit(flights_train)
# Get the best model from cross validation
best_model = cvModel.bestModel
# Look at the stages in the best model
print(best_model.stages)
# Get the parameters for the LinearRegression object in the best model
best_model.stages[3].extractParamMap()
# Generate predictions on test data using the best model then calculate RMSE
predictions = best_model.transform(flights_test)
evaluator.evaluate(predictions)
SMS spam optimized
The pipeline you built earlier for the SMS spam model used the default parameters for all of the elements in the pipeline. It's very unlikely that these parameters will give a particularly good model though.
In this exercise you'll set up a parameter grid which can be used with cross validation to choose a good set of parameters for the SMS spam classifier.
params = ParamGridBuilder()
# Add grid for hashing trick parameters
params = params.addGrid(hasher.numFeatures, (1024, 4096, 16384))\
.addGrid(hasher.binary, (True, False))
# Add grid for logistic regression parameters
params = params.addGrid(logistic.regParam, (0.01, 0.1, 1.0, 10.0))\
.addGrid(logistic.elasticNetParam, (0.0, 0.5, 1.0))
# Build parameter grid
params = params.build()
print('Number of models to be tested: ', len(params))
Ensemble
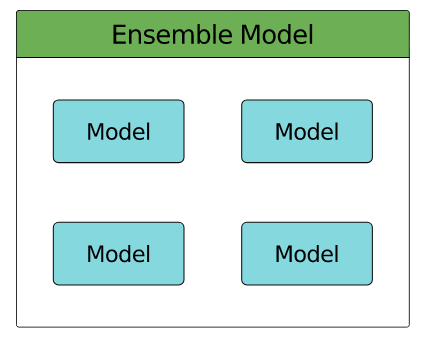
- collection of models
- Wisdom of the Crowd - collective opinion of a group better than that of a single expert
- Random Forest
- an ensemble of Decision Tree
- Creating model diversity
- each tree trained on random subset of data
- random subset of features used for splitting at each node
- No two trees in the forest should be the same
- Gradient-Boosted Trees
- Iterative boosting algorithm:
- Build a Decision Tree and add to ensemble
- Predict label for each training instance using ensemble
- Compare predictions with known labels
- Emphasize training instances with incorrect predictions
- return to 1.
- Iterative boosting algorithm:
from pyspark.ml.classification import RandomForestClassifier, GBTClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
assembler = VectorAssembler(inputCols=['mon', 'depart', 'duration'], outputCol='features')
flights = assembler.transform(flights.drop('features'))
flights = flights.withColumn('label', (flights.delay >= 15).cast('integer'))
flights = flights.select('mon', 'depart', 'duration', 'features', 'label')
flights = flights.dropna()
flights.show(5)
from pyspark.ml.classification import DecisionTreeClassifier, GBTClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pprint import pprint
flights_train, flights_test = flights.randomSplit([0.8, 0.2])
# Create model objects and train on training data
tree = DecisionTreeClassifier().fit(flights_train)
gbt = GBTClassifier().fit(flights_train)
# Compare AUC on test data
evaluator = BinaryClassificationEvaluator()
evaluator.evaluate(tree.transform(flights_test))
evaluator.evaluate(gbt.transform(flights_test))
# Find the number of trees and the relative importance of features
pprint(gbt.trees)
print(gbt.featureImportances)
Delayed flights with a Random Forest
In this exercise you'll bring together cross validation and ensemble methods. You'll be training a Random Forest classifier to predict delayed flights, using cross validation to choose the best values for model parameters.
You'll find good values for the following parameters:
-
featureSubsetStrategy— the number of features to consider for splitting at each node and -
maxDepth— the maximum number of splits along any branch.
from pyspark.ml.classification import RandomForestClassifier
# Create a random forest classifier
forest = RandomForestClassifier()
# Create a parameter grid
params = ParamGridBuilder() \
.addGrid(forest.featureSubsetStrategy, ['all', 'onethird', 'sqrt', 'log2']) \
.addGrid(forest.maxDepth, [2, 5, 10]) \
.build()
# Create a binary classification evaluator
evaluator = BinaryClassificationEvaluator()
# Create a cross-validator
cv = CrossValidator(estimator=forest, estimatorParamMaps=params,
evaluator=evaluator, numFolds=5)
cvModel = cv.fit(flights_train)
# Average AUC for each parameter combination in grid
avg_auc = cvModel.avgMetrics
# Average AUC for the best model
best_model_auc = max(avg_auc)
# What's the optimal paramter value?
opt_max_depth = cvModel.bestModel.explainParam('maxDepth')
opt_feat_substrat = cvModel.bestModel.explainParam('featureSubsetStrategy')
# AUC for best model on test data
best_auc = evaluator.evaluate(cvModel.transform(flights_test))
print(best_auc)