Going Deeper
By the end of this chapter, you will know how to solve binary, multi-class, and multi-label problems with neural networks. All of this by solving problems like detecting fake dollar bills, deciding who threw which dart at a board, and building an intelligent system to water your farm. You will also be able to plot model training metrics and to stop training and save your models when they no longer improve. This is the Summary of lecture "Introduction to Deep Learning with Keras", via datacamp.




import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.figsize'] = (8, 8)
Exploring dollar bills
You will practice building classification models in Keras with the Banknote Authentication dataset.
Your goal is to distinguish between real and fake dollar bills. In order to do this, the dataset comes with 4 features: variance,skewness,curtosis and entropy. These features are calculated by applying mathematical operations over the dollar bill images. The labels are found in the dataframe's class column.

banknotes = pd.read_csv('./dataset/banknotes.csv')
banknotes.head()
X = banknotes.iloc[:, :4]
X = ((X - X.mean()) / X.std()).to_numpy()
y = banknotes['class'].to_numpy()
sns.pairplot(banknotes, hue='class');

print('Dataset stats: \n', banknotes.describe())
# Count the number of observations per class
print('Observations per class: \n', banknotes['class'].value_counts())
Your pairplot shows that there are features for which the classes spread out noticeably. This gives us an intuition about our classes being easily separable. Let's build a model to find out what it can do!
A binary classification model
Now that you know what the Banknote Authentication dataset looks like, we'll build a simple model to distinguish between real and fake bills.
You will perform binary classification by using a single neuron as an output. The input layer will have 4 neurons since we have 4 features in our dataset. The model's output will be a value constrained between 0 and 1.
We will interpret this output number as the probability of our input variables coming from a fake dollar bill, with 1 meaning we are certain it's a fake bill.
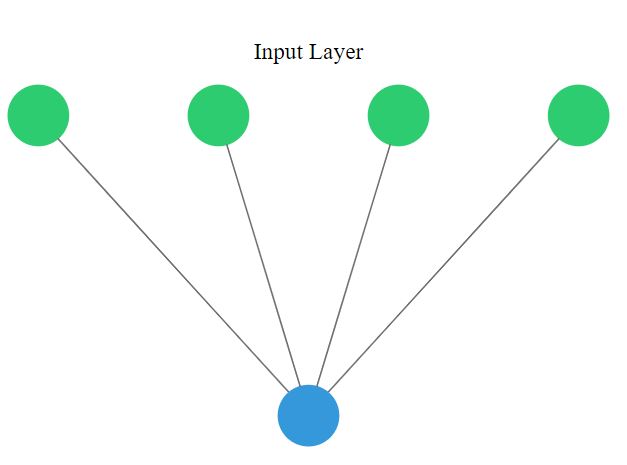
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# Create a sequential model
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4, ), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Display a summary of your model
model.summary()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y)
model.fit(X_train, y_train, epochs=20)
# Evaluate your model accuracy on the test set
accuracy = model.evaluate(X_test, y_test)[1]
# Print accuracy
print('Accuracy: ', accuracy)
A multi-class model
You're going to build a model that predicts who threw which dart only based on where that dart landed! (That is the dart's x and y coordinates on the board.)
This problem is a multi-class classification problem since each dart can only be thrown by one of 4 competitors. So classes/labels are mutually exclusive, and therefore we can build a neuron with as many output as competitors and use the softmax activation function to achieve a total sum of probabilities of 1 over all competitors.
darts = pd.read_csv('./dataset/darts.csv')
darts.head()
sns.pairplot(darts, hue='competitor');

model = Sequential()
# Add 3 dense layers of 128, 64, 32, neurons each
model.add(Dense(128, input_shape=(2, ), activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
# Add a dense layer with as many neurons as competitors
model.add(Dense(4, activation='softmax'))
# Compile your model using categorical_crossentropy loss
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
Prepare your dataset
In the console you can check that your labels, darts.competitor are not yet in a format to be understood by your network. They contain the names of the competitors as strings. You will first turn these competitors into unique numbers,then use the to_categorical() function from tf.keras.utils to turn these numbers into their one-hot encoded representation.
This is useful for multi-class classification problems, since there are as many output neurons as classes and for every observation in our dataset we just want one of the neurons to be activated.
from tensorflow.keras.utils import to_categorical
# Transform into a categorical variable
darts.competitor = pd.Categorical(darts.competitor)
# Assign a number to each category (label encoding)
darts.competitor = darts.competitor.cat.codes
# Print the label encoded competitors
print('Label encoded competitors: \n', darts.competitor.head())
coordinates = darts.drop(['competitor'], axis=1)
# Use to_categorical on your labels
competitors = to_categorical(darts.competitor)
# Now print the one-hot encoded labels
print('One-hot encoded competitors: \n', competitors)
Each competitor is now a vector of length 4, full of zeroes except for the position representing her or himself.
Training on dart throwers
Your model is now ready, just as your dataset. It's time to train!
The coordinates features and competitors labels you just transformed have been partitioned into coord_train,coord_test and competitors_train,competitors_test.
Let's find out who threw which dart just by looking at the board!
coordinates = darts[['xCoord', 'yCoord']]
coordinates.head()
coord_train, coord_test, competitors_train, competitors_test = \
train_test_split(coordinates, competitors, test_size=0.25, stratify=competitors)
model.summary()
model.fit(coord_train, competitors_train, epochs=200)
# Evaluate your model accuracy on the test data
accuracy = model.evaluate(coord_test, competitors_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
Softmax predictions
This model is generalizing well!, that's why you got a high accuracy on the test set.
Since you used the softmax activation function, for every input of 2 coordinates provided to your model there's an output vector of 4 numbers. Each of these numbers encodes the probability of a given dart being thrown by one of the 4 possible competitors.
When computing accuracy with the model's .evaluate() method, your model takes the class with the highest probability as the prediction. np.argmax() can help you do this since it returns the index with the highest value in an array.
Use the collection of test throws stored in coords_small_test and np.argmax() to check this out!
coords_small_test = pd.DataFrame({
'xCoord':[0.209048, 0.082103, 0.198165, -0.348660, 0.214726],
'yCoord':[-0.077398, -0.721407, -0.674646, 0.035086, 0.183894]
})
competitors_small_test = np.array([[0., 0., 1., 0.], [0., 0., 0., 1.],
[0., 0., 0., 1.], [1., 0., 0., 0.],
[0., 0., 1., 0.]])
preds = model.predict(coords_small_test)
# Print preds vs true values
print("{:45} | {}".format("Raw Model Predictions", "True labels"))
for i, pred in enumerate(preds):
print("{} | {}".format(pred, competitors_small_test[i]))
preds_chosen = [np.argmax(pred) for pred in preds]
# Print preds vs true values
print("{:10} | {}".format("Rounded Model Predictions", "True labels"))
for i, pred in enumerate(preds_chosen):
print("{:25} | {}".format(pred, competitors_small_test[i]))
As you've seen you can easily interpret the softmax output. This can also help you spot those observations where your network is less certain on which class to predict, since you can see the probability distribution among classes per prediction. Let's learn how to solve new problems with neural networks!
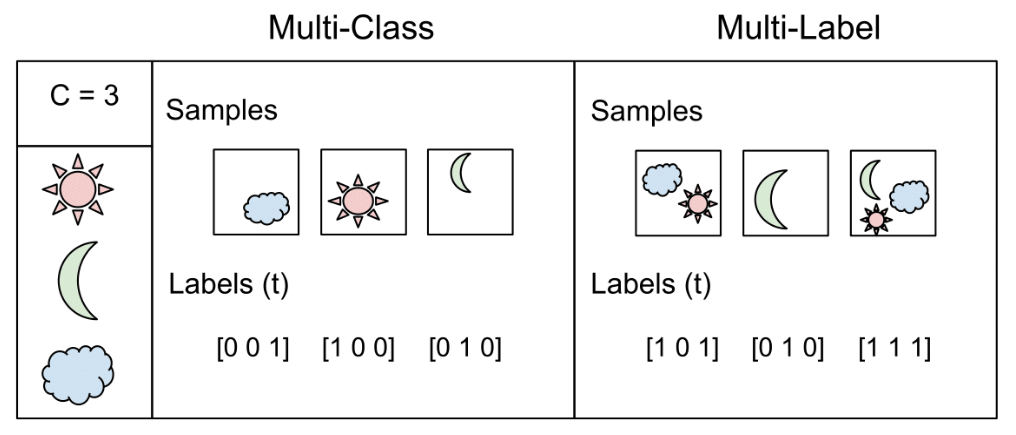
An irrigation machine
You're going to automate the watering of farm parcels by making an intelligent irrigation machine. Multi-label classification problems differ from multi-class problems in that each observation can be labeled with zero or more classes. So classes/labels are not mutually exclusive, you could water all, none or any combination of farm parcels based on the inputs.
To account for this behavior what we do is have an output layer with as many neurons as classes but this time, unlike in multi-class problems, each output neuron has a sigmoid activation function. This makes each neuron in the output layer able to output a number between 0 and 1 independently.
irrigation = pd.read_csv('./dataset/irrigation_machine.csv', index_col=0)
irrigation.head()
model = Sequential()
# Add a hidden layer of 64 neurons and a 20 neuron's input
model.add(Dense(64, input_shape=(20, ), activation='relu'))
# Add an output layer of 3 neurons with sigmoid activation
model.add(Dense(3, activation='sigmoid'))
# Compile your model with binary crossentropy loss
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
You've already built 3 models for 3 different problems! Hopefully you're starting to get a feel for how different problems can be modeled in the neural network realm.
Training with multiple labels
An output of your multi-label model could look like this: [0.76 , 0.99 , 0.66 ]. If we round up probabilities higher than 0.5, this observation will be classified as containing all 3 possible labels [1,1,1]. For this particular problem, this would mean watering all 3 parcels in your farm is the right thing to do, according to the network, given the input sensor measurements.
You will now train and predict with the model you just built. sensors_train, parcels_train, sensors_test and parcels_test are already loaded for you to use.
Let's see how well your intelligent machine performs!
parcels = irrigation[['parcel_0', 'parcel_1', 'parcel_2']].to_numpy()
sensors = irrigation.drop(['parcel_0', 'parcel_1', 'parcel_2'], axis=1).to_numpy()
sensors_train, sensors_test, parcels_train, parcels_test = \
train_test_split(sensors, parcels, test_size=0.3, stratify=parcels)
model.fit(sensors_train, parcels_train, epochs=100, validation_split=0.2)
# Predict on sensors_test and round up the predictions
preds = model.predict(sensors_test)
preds_rounded = np.round(preds)
# Print rounded preds
print('Rounded Predictions: \n', preds_rounded)
# Evaluate your model's accuracy on the test data
accuracy = model.evaluate(sensors_test, parcels_test)[1]
# Print accuracy
print('Accuracy:', accuracy)
Great work on automating this farm! You can see how the validation_split argument is useful for evaluating how your model performs as it trains. Let's move on and improve your model training by using callbacks!
The history callback
The history callback is returned by default every time you train a model with the .fit() method. To access these metrics you can access the history dictionary parameter inside the returned h_callback object with the corresponding keys.
The irrigation machine model you built in the previous lesson is loaded for you to train, along with its features and labels now loaded as X_train, y_train, X_test, y_test. This time you will store the model's history callback and use the validation_data parameter as it trains.
Let's see the behind the scenes of our training!
def plot_accuracy(acc,val_acc):
# Plot training & validation accuracy values
plt.figure();
plt.plot(acc);
plt.plot(val_acc);
plt.title('Model accuracy');
plt.ylabel('Accuracy');
plt.xlabel('Epoch');
plt.legend(['Train', 'Test'], loc='upper left');
def plot_loss(loss,val_loss):
plt.figure();
plt.plot(loss);
plt.plot(val_loss);
plt.title('Model loss');
plt.ylabel('Loss');
plt.xlabel('Epoch');
plt.legend(['Train', 'Test'], loc='upper right');
X_train, y_train = sensors_train, parcels_train
X_test, y_test = sensors_test, parcels_test
tf.keras, ’accuracy’ and ’val_accuracy’ is used for check accuracy
h_callback = model.fit(X_train, y_train, epochs=50, validation_data=(X_test, y_test))
plot_loss(h_callback.history['loss'], h_callback.history['val_loss'])
# Plot train vs test accuracy during training
#
plot_accuracy(h_callback.history['accuracy'], h_callback.history['val_accuracy'])


Early stopping your model
The early stopping callback is useful since it allows for you to stop the model training if it no longer improves after a given number of epochs. To make use of this functionality you need to pass the callback inside a list to the model's callback parameter in the .fit() method.
The model you built to detect fake dollar bills is loaded for you to train, this time with early stopping. X_train, y_train, X_test and y_test are also available for you to use.
X = banknotes.iloc[:, :4]
X = ((X - X.mean()) / X.std()).to_numpy()
y = banknotes['class'].to_numpy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y)
model = Sequential()
# Add a dense layer
model.add(Dense(1, input_shape=(4, ), activation='sigmoid'))
# Compile your model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
from tensorflow.keras.callbacks import EarlyStopping
# Define a callback to monitor val_acc
monitor_val_acc = EarlyStopping(monitor='val_accuracy', patience=5)
# Train your model using early stopping callback
model.fit(X_train, y_train, epochs=100, validation_data=(X_test, y_test),
callbacks=[monitor_val_acc]);
A combination of callbacks
Deep learning models can take a long time to train, especially when you move to deeper architectures and bigger datasets. Saving your model every time it improves as well as stopping it when it no longer does allows you to worry less about choosing the number of epochs to train for. You can also restore a saved model anytime and resume training where you left it.
Use the EarlyStopping() and the ModelCheckpoint() callbacks so that you can go eat a jar of cookies while you leave your computer to work!
from tensorflow.keras.callbacks import ModelCheckpoint
# Early stop on validation accuracy
monitor_val_acc = EarlyStopping(monitor='val_accuracy', patience=3)
# Save the best model as best_banknote_model.hdf5
modelCheckpoint = ModelCheckpoint('./best_banknote_model.hdf5', save_best_only=True)
# Fit your model for a stupid amount of epochs
h_callback = model.fit(X_train, y_train,
epochs=100000000000,
callbacks=[monitor_val_acc, modelCheckpoint],
validation_data=(X_test, y_test))
!ls | grep best_banknote*
Now you always save the model that performed best, even if you early stopped at one that was already performing worse.