RNN - Many-to-one stacking
In this post, We will extend the many-to-one RNN model with stacked version. And it will show the simple implementation in tensorflow.




import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
print('Tensorflow: {}'.format(tf.__version__))
plt.rcParams['figure.figsize'] = (16, 10)
plt.rc('font', size=15)
What is "stacking"
Previously, we covered the many-to-one type RNN model, which can classify the word tokens.
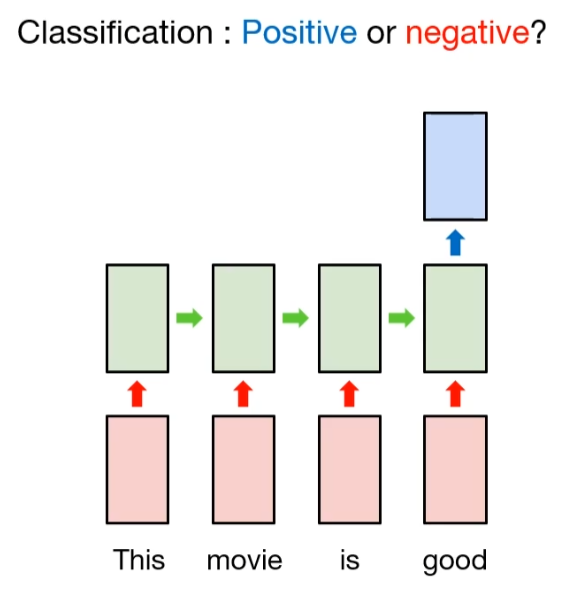
But what about more complex element, like setence? Of course, same process will be happened. But as you noticed, sometimes the meaning of word in specific sentence is different from meaning of word itself. For example, not contains negative meaning, but not bad intends positive meaning. Like this, we need to take a different approach in sentence classification.
In order to do this, the complex RNN model is required. More deeper, and more complex. Of course, it is not theoretically clear that has more advanced performance in deep model, but we can easily see the performance improvement in deep model on CNN archiecture. (See the example of AlexNet and VGG19)
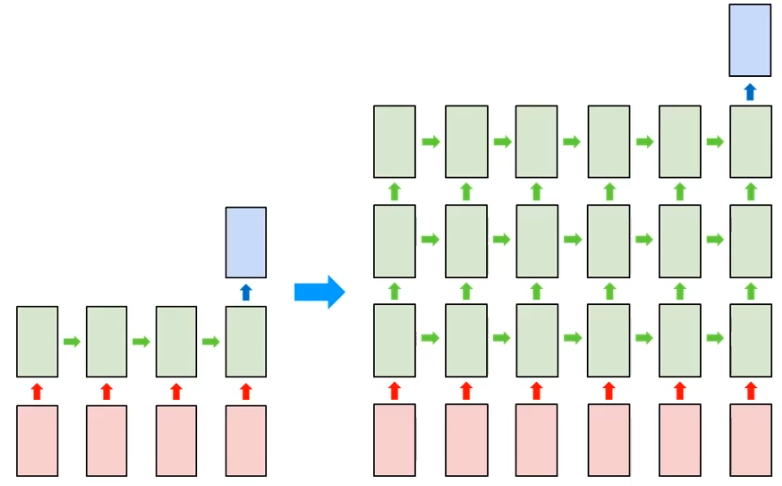
And here is deeper version of many-to-one that consists of multi-layered RNNs. It is also called "stacking" since multi-layered RNN is some kind of stacked RNN layer.
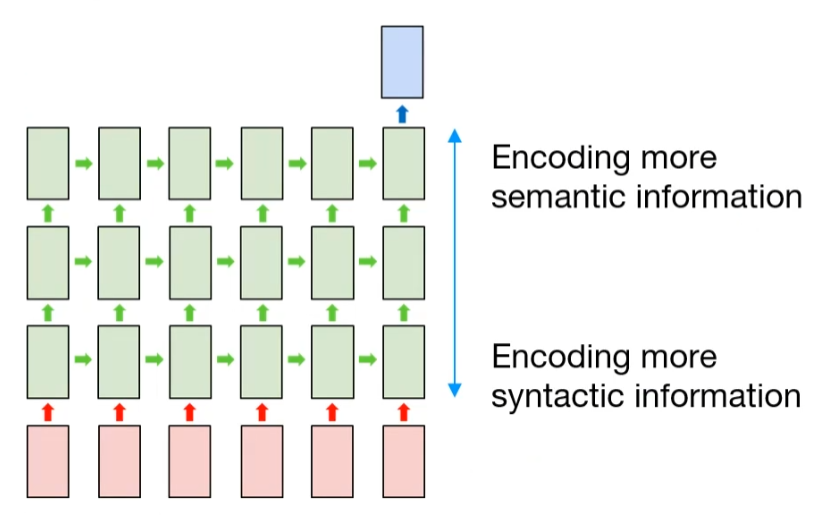
Usually, the hidden layer which close to output layer tends to encode more semantic information. And the hidden layer that close to input layer tends to encode more syntactic information. It means that the hidden layer in input side is concerned with the amount of data, and the hidden layer in output side concerned the meaning of the data.
Example - sentence classification
In this example, we will implement stacked RNN model for sentence classification. At first, we prepare the sentence data, and its purpose is to clasify the speaker of sentence. If the sentence is spoken by richard feynman, the label will be 1, and if albert einstein told the target sentence, the label will be 0.
sentences = ['What I cannot create, I do not understand',
'Intellectuals solve problems, geniuses prevent them',
'A person who never made a mistake never tied anything new.',
'The same equations have the same solutions']
y = [1, 0, 0, 1]
Same as previous example, we can build token dictionary.
char_set = ['<pad>'] + sorted(list(set(''.join(sentences))))
idx2char = {idx: char for idx, char in enumerate(char_set)}
char2idx = {char: idx for idx, char in enumerate(char_set)}
Of course, character set will be larger than before.
char_set
idx2char
char2idx
Based on this mapping, we can build training dataset, same as before.
X = list(map(lambda sentence: [char2idx.get(char) for char in sentence], sentences))
print(X)
Maybe the length of sentence is different from each other. And it requires padding that fix the format.
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_sequence = 55
X = pad_sequences(sequences=X, maxlen=max_sequence, padding='post', truncating='post')
print(X)
print(y)
train_ds = tf.data.Dataset.from_tensor_slices((X, y)).shuffle(buffer_size=4).batch(batch_size=2)
print(train_ds)
In order to implement stacked many-to-one model, it is very simple. Just add the hidden layer from 1 to more. And here is new kind of layers, TimeDistributed. Stacked RNN requires to handle sequence data. So first hidden layer sets the return_sequences to True. That is, outputs are generated sequentially. And to update the weight related on sequential data, this layer allows to apply a layer to every temporal slice of an input. And Dropout is used to avoid overfitting.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, TimeDistributed, Dropout, Dense
input_dim = len(char2idx)
output_dim = len(char2idx)
model = Sequential([
Embedding(input_dim=input_dim, output_dim=output_dim,
trainable=False, mask_zero=True, input_length=max_sequence,
embeddings_initializer=tf.keras.initializers.random_normal()),
SimpleRNN(units=10, return_sequences=True),
TimeDistributed(Dropout(rate=0.2)),
SimpleRNN(units=10),
Dense(units=2)
])
model.summary()
def loss_fn(model, x, y):
return tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=model(x), from_logits=True
))
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
tr_loss_hist = []
for e in range(30):
avg_tr_loss = 0
tr_step = 0
for x_mb, y_mb in train_ds:
with tf.GradientTape() as tape:
tr_loss = loss_fn(model, x=x_mb, y=y_mb)
grads = tape.gradient(target=tr_loss, sources=model.trainable_variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
avg_tr_loss += tr_loss
tr_step += 1
avg_tr_loss /= tr_step
tr_loss_hist.append(avg_tr_loss)
if (e + 1) % 5 == 0:
print('epoch: {:3}, tr_loss: {:.3f}'.format(e + 1, avg_tr_loss.numpy()))
After that, train loss is decreased by 0.005. Also we can get almost 100% accuracy.
prediction = model.predict(X)
prediction = np.argmax(prediction, axis=-1)
print('Accuracy: {:.2%}'.format(np.mean(prediction == y)))
plt.figure()
plt.plot(tr_loss_hist)
plt.title('Training loss of sentence classification')
plt.show()
