RNN - Many-to-many bidirectional
In this post, We will extend the many-to-many RNN model with bidirectional version. And it will show the simple implementation in tensorflow.




import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
print('Tensorflow: {}'.format(tf.__version__))
plt.rcParams['figure.figsize'] = (16, 10)
plt.rc('font', size=15)
CUDNN_STATUS_INTERNAL_ERROR. See the details from here. To prevent this, we need to set gpu configuration.
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
What is "bidirectional"?
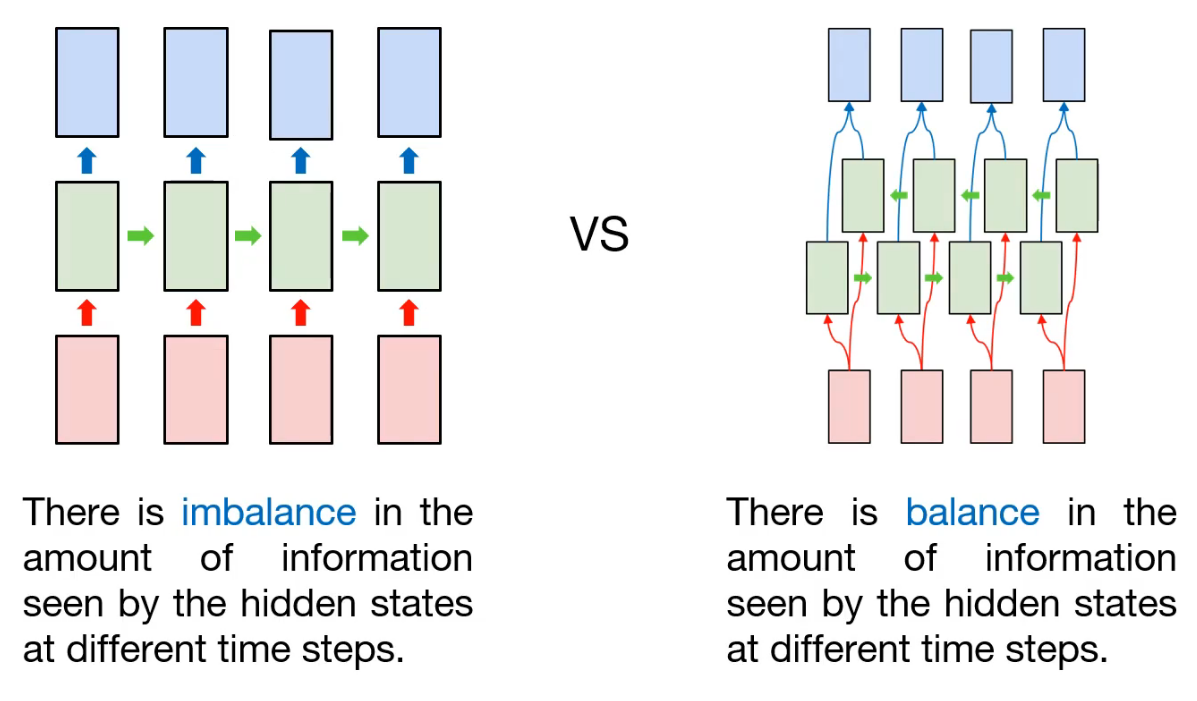
In previous post, we learned (basic) many-to-many rnn model, and implemented it for Part-of-Speech (POS) Tagging.
As we already know, the input is sequential data and hidden node is connected sequentially. That is, information contained in each node may be different. For example, assume that first token is consumed in first hidden node, and the information (maybe state information) will be transfered to the next hidden node, and so on. This process is repeated, and at last, the last hidden node will containe lots of information compared with previous node's. In that case, there is imbalance in the amount of information seen by the hidden states at different time steps.
So how can we prevent this? One approach is to add another hidden layer for information balance. So the information obtained from last token will be propagated to first hidden node. As a result, there are two kinds of hidden layer: the forward-pass, and the backward-pass. That's why we call this kind of model to "Bidirectional".
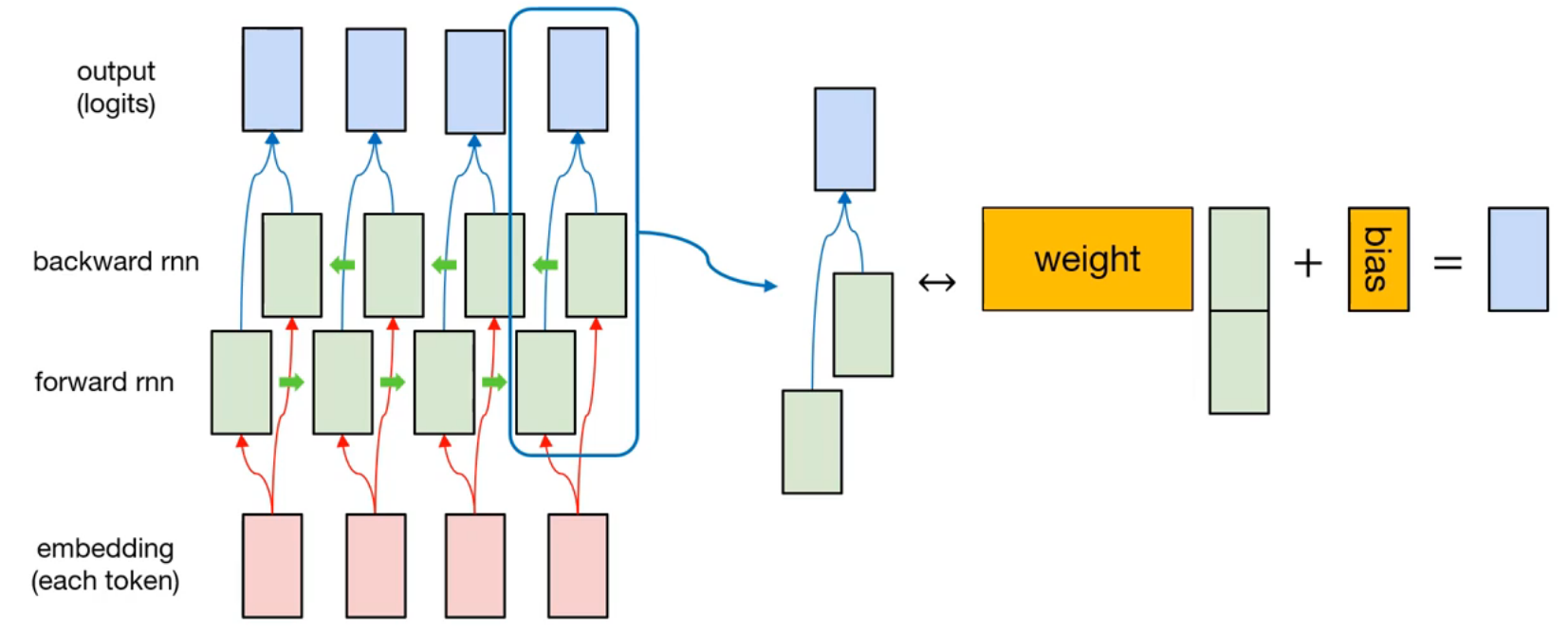
The detailed representation is like this. There are two hidden layers, forward rnn and backward rnn. At each time step, the hidden node from forward rnn and the hidden node from backward rnn is concatenated. Then, it will multiply with weight of node, and adding the bias. After that, output is generated.
Since this model is also many-to-many rnn model, the sequence loss is used.
sentences = [['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for', 'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast', 'changing']]
pos = [['pronoun', 'verb', 'adjective'],
['noun', 'verb', 'adverb', 'adjective'],
['noun', 'verb', 'determiner', 'noun', 'preposition', 'adjective', 'noun'],
['noun', 'verb', 'adverb', 'adjective', 'verb']]
word_list = ['<pad>'] + sorted(set(sum(sentences, [])))
word2idx = {word:idx for idx, word in enumerate(word_list)}
idx2word = {idx:word for idx, word in enumerate(word_list)}
print(word2idx)
print(idx2word)
pos_list = ['<pad>'] + sorted(set(sum(pos, [])))
pos2idx = {pos:idx for idx, pos in enumerate(pos_list)}
idx2pos = {idx:pos for idx, pos in enumerate(pos_list)}
print(pos2idx)
print(idx2pos)
Same as before, we build the token/POS dictionary. And we need to consider padding token. So we make a masking vector for filtering padding token.
X = list(map(lambda sentence: [word2idx.get(token) for token in sentence], sentences))
y = list(map(lambda sentence: [pos2idx.get(token) for token in sentence], pos))
print(X)
print(y)
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(X, maxlen=10, padding='post')
X_mask = (X != 0).astype(np.float32)
X_len = np.array(list((map(lambda sentence: len(sentence), sentences))), dtype=np.float32)
print(X)
print(X_mask)
print(X_len)
y = pad_sequences(y, maxlen=10, padding='post')
print(y)
train_ds = tf.data.Dataset.from_tensor_slices((X, y, X_len)).shuffle(buffer_size=4).batch(batch_size=2)
print(train_ds)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import InputLayer, Embedding, Bidirectional, SimpleRNN, TimeDistributed, Dense
num_classes = len(pos2idx)
input_dim = len(word2idx)
output_dim = len(word2idx)
model = Sequential([
InputLayer(input_shape=(10, )),
Embedding(input_dim=input_dim, output_dim=output_dim, mask_zero=True,
trainable=False, input_length=10,
embeddings_initializer=tf.keras.initializers.random_normal()),
Bidirectional(SimpleRNN(units=10, return_sequences=True)),
TimeDistributed(Dense(units=num_classes))
])
model.summary()
def loss_fn(model, x, y, x_len, max_sequence):
masking = tf.sequence_mask(x_len, maxlen=max_sequence, dtype=tf.float32)
sequence_loss = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=model(x), from_logits=True) * masking
sequence_loss = tf.reduce_mean(tf.reduce_sum(sequence_loss, axis=-1) / x_len)
return sequence_loss
optimizer = tf.keras.optimizers.Adam(learning_rate=0.1)
tr_loss_hist = []
for e in range(30):
avg_tr_loss = 0
tr_step = 0
for x_mb, y_mb, x_mb_len in train_ds:
with tf.GradientTape() as tape:
tr_loss = loss_fn(model, x_mb, y_mb, x_mb_len, 10)
grads = tape.gradient(target=tr_loss, sources=model.trainable_variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
avg_tr_loss += tr_loss
tr_step += 1
avg_tr_loss /= tr_step
tr_loss_hist.append(avg_tr_loss)
if (e + 1) % 5 == 0:
print('Epoch: {:3}, tr_loss: {:.3f}'.format(e + 1, avg_tr_loss))
Compared with the result from basic many-to-many model, training loss is slightly decreased. Then, let's check the performance.
y_pred = model.predict(X)
y_pred = np.argmax(y_pred, axis=-1) * X_mask
y_pred
from pprint import pprint
y_pred_pos = list(map(lambda row: [idx2pos.get(elm) for elm in row], y_pred.astype(np.int32).tolist()))
pprint(y_pred_pos)
pprint(pos)
plt.figure()
plt.plot(tr_loss_hist)
plt.title('Training loss for many-to-many bidirectional model')
plt.show()

Summary
Through this post, in order to handle the information imbalance while processing sequence data, another rnn layer is added. So the information is transfered in 2 ways (forward-pass and backward-pass).
we try to implement this kind of bidirectional many-to-many model with tensorflow, and train it for POS tagging. Interestingly, the training speed is slightly faster than base model, and it also show 100% accuracy on training dataset.