Introduction to Natural Language Processing
In this post, we will dig into the strong NLP foundation through basic concepts like Tokenization, Stopword handling, Stemming and so on. We will use sklearn with Natural Language ToolKit (NLTK) package, which is widely used in NLP area.




- Introduction
- Required packages
- Notation
- Version check
- Tokenization
- Stop words
- Stemming
- Part of Speech Tagging (POS)
- Chunking
- Chinking
- Named Entity Recognition (NER)
- Text Classification
- Summary
Introduction
Natural-language processing (NLP) is an area of computer science and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to fruitfully process large amounts of natural language data (wikipedia).
This rapidly improving area of artificial intelligence covers tasks such as speech recognition, natural-language understanding, and natural language generation.
In the following projects, we're going to be building a strong NLP foundation by practicing:
- Tokenizing - Splitting sentences and words from the body of text.
- Part of Speech tagging
- Chunking
This foundation will open the door for machine learning in conjunction with NLP. We will cover:
- Machine learning in NLP
- How to tie in Scikit-learn (sklearn) with NLTK
- Training classifiers with a datasets (Next Project)
Let's dive right in! We are going to be using the Natural Language Toolkit (NLTK) which is a suite of libraries and programs for symbolic and statistical natural language processing for English written in the Python programming language
import nltk
import sys
import sklearn
nltk.download()
After that, you may see some GUI form to download some packages. The efficient way to process NLP is selecting "popular" option. Then it will download and install required packages and Corpora.
We need more corporas for this post. Choose the next menu in Corpora, and install following things,
state_unionudhr2udhr
Notation
Before beginning, Some words will not be familiar with us like corpus, Lexicon, and Token. Corpus is the body of text. It is singular. Corpora is the plural of this. Lexicon is the set of words and its meanings. And Token means each "entity" that is a part of whatever was split up based on specific rules. For example, We can tokenize the word based on stem, or space.
print('Python: {}'.format(sys.version))
print('NLTK: {}'.format(nltk.__version__))
print('Scikit-learn: {}'.format(sklearn.__version__))
Tokenization
When using Natural Language Processing, our goal is to perform some analysis or processing so that a computer can respond to text appropriately.
The process of converting data to something a computer can understand is referred to as "pre-processing." One of the major forms of pre-processing is going to be filtering out useless data. In natural language processing, useless words (data), are referred to as stop words.
from nltk.tokenize import sent_tokenize, word_tokenize
text = "Hello students, how are you doing today? The olympics are inspiring, and Python is awesome. You look nice today."
If we want to tokenize this sentence,
sent_tokenize(text)
You can see 3 sentence by tokenizing. Maybe we guess that it is tokenized by the Capital letter.
Next, if you want the word that containing this sentense,
word_tokenize(text)
You can see almost all words in sentence is tokenized, but some specific characters are also contained like ",", "?", ".". These are called puncutation. Of course, these are important to understand the intension of sentence. But we'll cover it later.
Stop words
When using Natural Language Processing, our goal is to perform some analysis or processing so that a computer can respond to text appropriately.
The process of converting data to something a computer can understand is referred to as "pre-processing." One of the major forms of pre-processing is going to be filtering out useless data. In natural language processing, useless words (data), are referred to as stop words. Of course, it would be different in each language, in this post we will use english stop words.
from nltk.corpus import stopwords
stopwords.words('english')
Mentioned before, it maybe important to understand the intension. But most of time, words in stopwords appears multiple times and it will be hard to understand the intension of sentence from computer side. So it is helpful to remove these words in advance. See what is different.
example_sent = "This is some sample text, showing off the stop words filtration."
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sent = [w for w in word_tokens if not w in stop_words]
print(word_tokens)
print(filtered_sent)
Stemming
Stemming, which attempts to normalize sentences, is another preprocessing step that we can perform. In the english language, different variations of words and sentences often having the same meaning. Stemming is a way to account for these variations; furthermore, it will help us shorten the sentences and shorten our lookup. For example, consider the following sentence:
- I was taking a ride on my horse.
- I was riding my horse.
These sentences mean the same thing, as noted by the same tense (-ing) in each sentence; however, that isn't intuitively understood by the computer. To account for all the variations of words in the english language, we can use the Porter stemmer, which has been around since 1979. You can see the details in this pages.
from nltk.stem import PorterStemmer
ps = PorterStemmer()
example_words = ['ride', 'riding', 'rider', 'rides']
for w in example_words:
print(ps.stem(w))
Usually, we can apply this in token, so we can analyze which words appears occasionally.
text = "When riders are riding their horses, they often think of how cowboys rode horses."
words = word_tokenize(text)
for w in words:
print(ps.stem(w))
Part of Speech Tagging (POS)
Part of speech tagging means labeling words as nouns, verbs, adjectives, etc. Even better, NLTK can handle tenses! While we're at it, we are also going to import a new sentence tokenizer (PunktSentenceTokenizer). This tokenizer is capable of unsupervised learning, so it can be trained on any body of text.
In this section, we will use pre-downloaded "Universal declaration of human rights" (udhr for short).
from nltk.corpus import udhr
print(udhr.raw('English-Latin1'))
Here, we will also import some corpus examples, - George Bush's 2005 and 2006 state of the union addresses.
from nltk.corpus import state_union
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
print(train_text[:1000])
Now we have some text, we can train the PunktSentenceTokenizer.
from nltk.tokenize import PunktSentenceTokenizer
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokens = custom_sent_tokenizer.tokenize(sample_text)
tokens
After that, we can tokenize each word in sentence. Now we need to tag each words with part of speech (also known as POS)
def process_content():
try:
for t in tokens[:5]:
words = nltk.word_tokenize(t)
tagged = nltk.pos_tag(words)
print(tagged)
except Exception as e:
print(str(e))
process_content()
Here, you can see tags are added after each words. Each tag means:
- POS: Possesive ending
- NNP: Proper noun, singular
- IN: Preposition or subordinating conjuntion
- NN: Noun, sigular or mass
- RB : Adverb
- VBP: Verb, non-3rd person sigular present
- ...
(The detailed list are found in here)
Or you can download the tagsets from nltk.download(). (All packages -> tagsets)
nltk.help.upenn_tagset()
Chunking
Now that each word has been tagged with a part of speech, we can move onto chunking, meaning that grouping the words into meaningful clusters. The main goal of chunking is to group words into "noun phrases", which is a noun with any associated verbs, adjectives, or adverbs.
The part of speech tags that were generated in the previous step will be combined with regular expressions, such as the following:
- $+$ = match 1 or more
- $?$ = match 0 or 1 repetitions.
- $*$ = match 0 or MORE repetitions
- $.$ = Any character except a new line
def process_content():
try:
for i in tokens[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
# combine the part-of-speech tag with a regular expression
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
# draw the chunks with nltk
chunked.draw()
except Exception as e:
print(str(e))
We build the chuck rule as follows:
$<\text{RB}.?>*$ = "0 or more of any tense of adverb," followed by:
$<\text{VB}.?>*$ = "0 or more of any tense of verb," followed by:
$<\text{NNP}>+$ = "One or more proper nouns," followed by
$<\text{NN}>?$ = "zero or one singular noun."
See what's going on.
process_content()
Maybe you can this kind of tree diagrams:

This diagram shows the hierarchical relationship between words and which words are grouping with some tokens.
Or we can print it inline, not showing in GUI.
def process_content():
try:
for i in tokens[:10]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
# combine the part-of-speech tag with a regular expression
chunkGram = r"""Chunk: {<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
# print the nltk tree
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
except Exception as e:
print(str(e))
process_content()
def process_content():
try:
for i in tokens[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
# The main difference here is the }{, vs. the {}. This means we're removing
# from the chink one or more verbs, prepositions, determiners, or the word 'to'.
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
# print(chunked)
for subtree in chunked.subtrees(filter=lambda t: t.label() == 'Chunk'):
print(subtree)
# chunked.draw()
except Exception as e:
print(str(e))
process_content()
For summary, using modified regular expressions, we can define chunk patterns. These are patterns of part-of-speech tags that define what kinds of words make up a chunk. We can also define patterns for what kinds of words should not be in a chunk. These unchunked words are known as chinks.
Named Entity Recognition (NER)
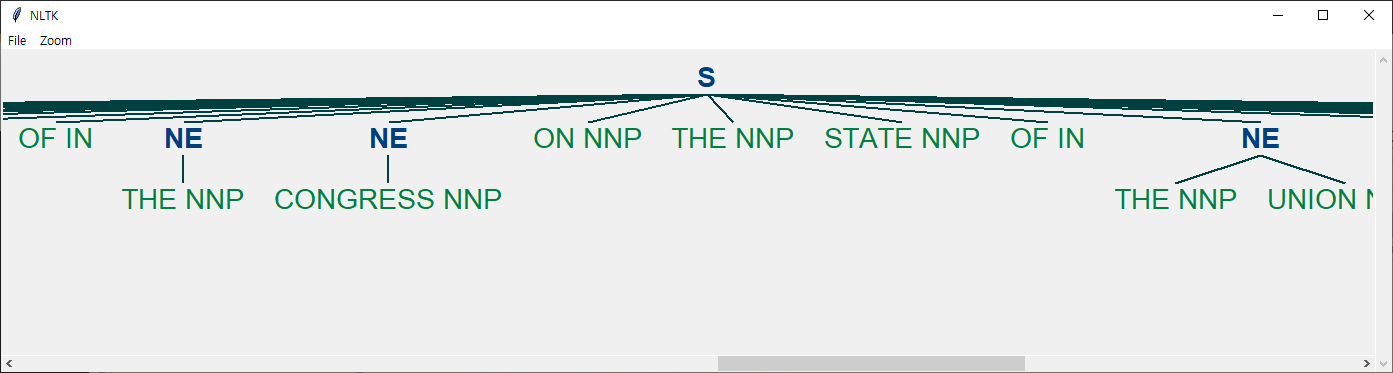
One of the most common forms of chunking in natural language processing is called Named Entity Recognition (NER for short). NLTK is able to identify people, places, things, locations, monetary figures, and more.
There are two major options with NLTK's named entity recognition: either recognize all named entities, or recognize named entities as their respective type, like people, places, locations, etc.
def process_content():
try:
for i in tokens[:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
namedEnt = nltk.ne_chunk(tagged, binary=True)
# print(chunked)
for subtree in namedEnt.subtrees(filter=lambda t: t.label() == 'NE'):
print(subtree)
# namedEnt.draw()
except Exception as e:
print(str(e))
process_content()
Same visualization we can see above.
Text Classification
Now, it's time to process text classification. All processes we've done is some kind of preprocessing the text data, like tokenization, stemming, POS tagging, chunking and chinking, and NER.
In this part, we will use movie review dataset in NLTK, one of famous NLP datasets. This datasets are commonly used to sentimental analysis. But we need to classify each words in advance.
from nltk.corpus import movie_reviews
import random
# Build documents
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
# Shuffle the documents
random.shuffle(documents)
print('Number of Documents: {}'.format(len(documents)))
print('First Review: {}'.format(documents[1]))
all_words = []
for w in movie_reviews.words():
all_words.append(w.lower())
# Generate frequency distribution
all_words = nltk.FreqDist(all_words)
print('\nMost common words: {}'.format(all_words.most_common(15)))
print('\nThe word happy: {}'.format(all_words["happy"]))
You can see that there are 215 "happy" words in movie_reviews. It means that that review maybe positive review. And you can also notice that the common words contain punctuation or stop words and so on.
Now we need to build features. In this post, we will use 4000 high frequent words as features.
word_features = list(all_words.keys())[:4000]
And it will be helpful to define the function that find the features.
def find_features(document):
words = set(document)
features = {}
for w in word_features:
features[w] = (w in words)
return features
Then Let's use an example from a negative review.
neg_features = find_features(movie_reviews.words('neg/cv000_29416.txt'))
for k, v in neg_features.items():
if v == True:
print(k)
Now redo this in whole documents.
featuresets = [(find_features(rev), category) for (rev, category) in documents]
After that, we will use Support Vector Classifier for text classification. Before classifcation, we need to make train and test set, same as usual.
from sklearn.model_selection import train_test_split
training, test = train_test_split(featuresets, test_size=0.25, random_state=1)
print(len(training), len(test))
Then, we use SVC from sklearn and SklearnClassifier from nltk.
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.svm import SVC
# Instantiate the model
model = SklearnClassifier(SVC(kernel='linear'))
# Train the model
model.train(training)
# Evaluate the model
accuracy = nltk.classify.accuracy(model, test)
print("SVC Accuracy: {}".format(accuracy))
As a result, we can build the text classifier model with almost 80% accuracy.