Cost Minimization using Gradient Descent
In this post, it will cover cost minimization using Gradient Descent.




- Hypothesis and cost function
- Gradient Descent Algorithm
- Cost function in pure Python
- Cost function in Tensorflow
- Gradient Descent in Tensorflow
- Summary
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 8)
plt.style.use('seaborn')
Hypothesis and cost function
From the previous post, we covered the definition of hypothesis and cost function(also known as Loss function)
$$ \text{Hypothesis: } \quad H(x) = Wx + b \\ \text{Cost: } \quad cost(W, b) = \frac{1}{m} \sum_{i=1}^m(H(x_i) - y_i)^2 $$
Actually, when we try to explain the hypothesis, we usually embed the bias term into the weight vector. So it just simplifies the form like this,
$$ \text{Hypothesis: } \quad H(x) = Wx \\ \text{Cost:} \quad cost(W) = \frac{1}{m} \sum_{i=1}^m(W x_i - y_i)^2 $$
Through the learning process, we want to find the optimal weight vector($W$) for minimizing cost function. As I explained earlier post, the common approach to find the minimum value is to calculate the gradient of each point,then find the pattern of decreasing(descent). This kind approach is called gradient descent, and it is used lots of minimization problems.
Gradient Descent Algorithm
The detailed process of gradient descent is like this:
-
Start with initial guess,
- Usually select 0,0 (but we can select other values at the beginning)
- Keeping changing $W$ and $b$ a little bit with learning rate to try and reduce cost
-
Each time, we can change its parameter, then we can calculate the gradient which reduces cost function the most possible
- Repeat
- Do so until it converge to a minimum
But actually, we can not sure that the minimum value that we found from Gradient Descent is global optimum. In some cases, the minimum value may be the local minimum.
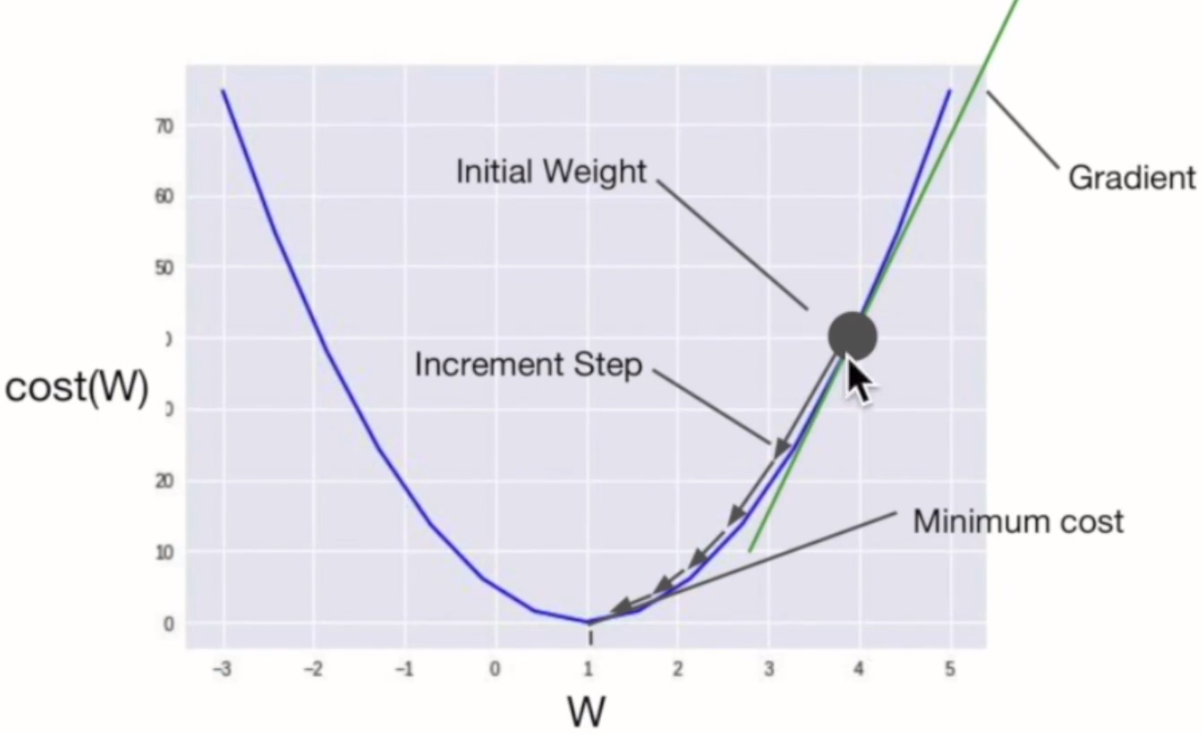
In the figure, it is easy to find the global minimum through Gradient descent. When we start with initial weights, through the direction of decreasing gradient, it updates its weights to find the point of minimum cost. Wherever we change the inital points, it may be found the global minimum point.
So, how can we update the weight while finding the minimum point? We use "gradient" for each data point, it requires derivates of cost function. The formal definition of weight update is mentioned below.
$$ \begin{aligned} W &:= W - \alpha * \frac{\partial}{\partial W} \frac{1}{2m} \sum_{i=1}^m (W(x_i) - y_i)^2 \\ &:= W - \alpha * \frac{1}{2m} \sum_{i=1}^{m} 2 (W (x_i) - y_i) x_i \\ & := W - \alpha \frac{1}{m} \sum_{i=1}^m (W(x_i) - y_i) x_i \end{aligned} $$
Here, $\alpha$ is learning rate. And there is a assumption in formal definition that coefficient of cost function is changed from $\frac{1}{m}$ to $\frac{1}{2m}$. That's because, when the derivate of 2nd order term generates 2, so it is easy to simplify the constant term when we have $2m$, and it is not affect too much in whole calculation.
As a result, weight vector is changed with respect to $\alpha$ while updating.
X = np.array([1, 2, 3])
Y = np.array([1, 2, 3])
# Cost function
def cost_func(W, X, Y):
c = 0
for x, y in zip(X, Y):
c += (W*x - y) ** 2
return c / len(X)
cost_hist = []
for feed_W in np.linspace(-3, 5, num=15):
curr_cost = cost_func(feed_W, X, Y)
cost_hist.append(curr_cost)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))
Through cost function, we calculated the MSE, and measured cost for each weight values. As you can see, cost is minimized when $W=1$. We can also confirm from the visualization of the cost value.
plt.figure(figsize=(10, 8));
plt.plot(np.linspace(-3, 5, num=15), cost_hist);
plt.title('Cost function');
plt.xlabel('W');
plt.ylabel('cost');

def cost_func_tf(W, X, Y):
h = X * W
return tf.reduce_mean(tf.square(h - Y))
W_values = np.linspace(-3, 5, num=15)
cost_hist = []
for feed_W in W_values:
curr_cost = cost_func_tf(feed_W, X, Y)
cost_hist.append(curr_cost)
print("{:6.3f} | {:10.5f}".format(feed_W, curr_cost))
We can get same result here as described before.
plt.figure(figsize=(10, 8));
plt.plot(np.linspace(-3, 5, num=15), cost_hist);
plt.title('Cost function with tf');
plt.xlabel('W');
plt.ylabel('cost');

Gradient Descent in Tensorflow
As we explained it earlier, we can express the gradient descent algorithm in Tensorflow. Remember that the definition of gradient descent is that,
$$ W := W - \alpha \frac{1}{m} \sum_{i=1}^m (W(x_i) -y_i) x_i $$
X = [1., 2., 3., 4.]
Y = [1., 3., 5., 7.]
W = tf.Variable(tf.random.normal([1], -100., 100.))
alpha = 0.01
cost_hist = []
W_hist = []
for e in range(300):
h = W * X
cost = tf.reduce_mean(tf.square(h - Y))
# Gradient Descent
gradient = tf.reduce_mean((W * X - Y) * X)
descent = W - alpha * gradient
# update weight
W.assign(descent)
if e % 10 == 0:
cost_hist.append(cost.numpy())
W_hist.append(W.numpy()[0])
print('{:5} | {:10.4f} | {:10.6f}'.format(e, cost.numpy(), W.numpy()[0]))
plt.figure(figsize=(10, 8));
plt.scatter(W_hist, cost_hist);
plt.plot(W_hist, cost_hist, color='red');
plt.axvline(x=min(W_hist), linestyle='--');

As you can see from the figure, Gradient Descent tends to find the $W$ for minimizing cost.
Summary
In this post, we tried to explain what the hypothesis and cost function (again!!), and we want to find the best Weight vector (and also bias) for minimizing error between hypothesis and actual data. To do this, Gradient Descent Algorithm is introduced, and test it with real code (both python and tensorflow)