Music Generation
In this post, We will take a hands-on-lab of Music Generation. This tutorial is the software lab, which is part of "introduction to deep learning 2021" offered from MIT 6.S191.




- Copyright Information
- Music Generation with RNNs
- Dataset
- Process the dataset for the learning task
- The Recurrent Neural Network (RNN) model
- Training the model: loss and training operations
- Generate music using the RNN model
- Experiment and get awarded for the best songs!
Copyright Information
Copyright 2021 MIT 6.S191 Introduction to Deep Learning. All Rights Reserved.
Licensed under the MIT License. You may not use this file except in compliance with the License. Use and/or modification of this code outside of 6.S191 must reference:
© MIT 6.S191: Introduction to Deep Learning http://introtodeeplearning.com
Music Generation with RNNs
In this portion of the lab, we will explore building a Recurrent Neural Network (RNN) for music generation. We will train a model to learn the patterns in raw sheet music in ABC notation and then use this model to generate new music.
import tensorflow as tf
import numpy as np
import os
import time
import regex as re
import subprocess
import urllib
import functools
from IPython import display as ipythondisplay
from tqdm import tqdm
import matplotlib.pyplot as plt
# Check that we are using a GPU, if not switch runtimes
# using Runtime > Change Runtime Type > GPU
assert len(tf.config.list_physical_devices('GPU')) > 0
cwd = os.getcwd()
def extract_song_snippet(text):
pattern = '(^|\n\n)(.*?)\n\n'
search_results = re.findall(pattern, text, overlapped=True, flags=re.DOTALL)
songs = [song[1] for song in search_results]
print("Found {} songs in text".format(len(songs)))
return songs
songs = []
with open(os.path.join(cwd, 'dataset', 'irish.abc'), 'r') as f:
text = f.read()
songs = extract_song_snippet(text)
# Print one of the songs to inspect it in greater detail!
example_song = songs[0]
print("\nExample song: ")
print(example_song)
We can easily convert a song in ABC notation to an audio waveform and play it back. Be patient for this conversion to run, it can take some time.
timidity and abc2midi on windows, it can be worked on windows. I`ve done this on windows jupyter environment
def save_song_to_abc(song, filename="tmp"):
save_name = "{}.abc".format(filename)
with open(save_name, "w") as f:
f.write(song)
return filename
def abc2wav(abc_file):
suf = abc_file.rstrip('.abc')
cmd = "abc2midi {} -o {}".format(abc_file, suf + ".mid")
os.system(cmd)
cmd = "timidity {}.mid -Ow {}.wav".format(suf, suf)
return os.system(cmd)
def play_wav(wav_file):
return ipythondisplay.Audio(wav_file)
def play_song(song):
basename = save_song_to_abc(song)
ret = abc2wav(basename + '.abc')
if ret == 0: #did not suceed
return play_wav(basename+'.wav')
return None
play_song(example_song)
One important thing to think about is that this notation of music does not simply contain information on the notes being played, but additionally there is meta information such as the song title, key, and tempo. How does the number of different characters that are present in the text file impact the complexity of the learning problem? This will become important soon, when we generate a numerical representation for the text data.
songs_joined = "\n\n".join(songs)
# Find all unique characters in the joined string
vocab = sorted(set(songs_joined))
print("There are", len(vocab), "unique characters in the dataset")
Process the dataset for the learning task
Let's take a step back and consider our prediction task. We're trying to train a RNN model to learn patterns in ABC music, and then use this model to generate (i.e., predict) a new piece of music based on this learned information.
Breaking this down, what we're really asking the model is: given a character, or a sequence of characters, what is the most probable next character? We'll train the model to perform this task.
To achieve this, we will input a sequence of characters to the model, and train the model to predict the output, that is, the following character at each time step. RNNs maintain an internal state that depends on previously seen elements, so information about all characters seen up until a given moment will be taken into account in generating the prediction.
Vectorize the text
Before we begin training our RNN model, we'll need to create a numerical representation of our text-based dataset. To do this, we'll generate two lookup tables: one that maps characters to numbers, and a second that maps numbers back to characters. Recall that we just identified the unique characters present in the text.
# Create a mapping from character to unique index.
# For example, to get the index of the character "d",
# we can evaluate `char2idx["d"]`.
char2idx = {u:i for i, u in enumerate(vocab)}
# Create a mapping from indices to characters. This is
# the inverse of char2idx and allows us to convert back
# from unique index to the character in our vocabulary.
idx2char = np.array(vocab)
This gives us an integer representation for each character. Observe that the unique characters (i.e., our vocabulary) in the text are mapped as indices from 0 to len(unique). Let's take a peek at this numerical representation of our dataset:
print('{')
for char,_ in zip(char2idx, range(20)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...\n}')
'''TODO: Write a function to convert the all songs string to a vectorized
(i.e., numeric) representation. Use the appropriate mapping
above to convert from vocab characters to the corresponding indices.
NOTE: the output of the `vectorize_string` function
should be a np.array with `N` elements, where `N` is
the number of characters in the input string
'''
def vectorize_string(string):
vectorized_list = np.array([char2idx[s] for s in string])
return vectorized_list
vectorized_songs = vectorize_string(songs_joined)
We can also look at how the first part of the text is mapped to an integer representation:
print ('{} ---- characters mapped to int ----> {}'.format(repr(songs_joined[:10]), vectorized_songs[:10]))
# check that vectorized_songs is a numpy array
assert isinstance(vectorized_songs, np.ndarray), "returned result should be a numpy array"
Create training examples and targets
Our next step is to actually divide the text into example sequences that we'll use during training. Each input sequence that we feed into our RNN will contain seq_length characters from the text. We'll also need to define a target sequence for each input sequence, which will be used in training the RNN to predict the next character. For each input, the corresponding target will contain the same length of text, except shifted one character to the right.
To do this, we'll break the text into chunks of seq_length+1. Suppose seq_length is 4 and our text is "Hello". Then, our input sequence is "Hell" and the target sequence is "ello".
The batch method will then let us convert this stream of character indices to sequences of the desired size.
def test_batch_func_types(func, args):
ret = func(*args)
assert len(ret) == 2, "[FAIL] get_batch must return two arguments (input and label)"
assert type(ret[0]) == np.ndarray, "[FAIL] test_batch_func_types: x is not np.array"
assert type(ret[1]) == np.ndarray, "[FAIL] test_batch_func_types: y is not np.array"
print("[PASS] test_batch_func_types")
return True
def test_batch_func_shapes(func, args):
dataset, seq_length, batch_size = args
x, y = func(*args)
correct = (batch_size, seq_length)
assert x.shape == correct, "[FAIL] test_batch_func_shapes: x {} is not correct shape {}".format(x.shape, correct)
assert y.shape == correct, "[FAIL] test_batch_func_shapes: y {} is not correct shape {}".format(y.shape, correct)
print("[PASS] test_batch_func_shapes")
return True
def test_batch_func_next_step(func, args):
x, y = func(*args)
assert (x[:,1:] == y[:,:-1]).all(), "[FAIL] test_batch_func_next_step: x_{t} must equal y_{t-1} for all t"
print("[PASS] test_batch_func_next_step")
return True
def get_batch(vectorized_songs, seq_length, batch_size):
# the length of the vectorized songs string
n = vectorized_songs.shape[0] - 1
# randomly choose the starting indices for the examples in the training batch
idx = np.random.choice(n-seq_length, batch_size)
'''TODO: construct a list of input sequences for the training batch'''
input_batch = [vectorized_songs[i:i+seq_length] for i in idx]
'''TODO: construct a list of output sequences for the training batch'''
output_batch = [vectorized_songs[i+1: i+1+seq_length] for i in idx]
# x_batch, y_batch provide the true inputs and targets for network training
x_batch = np.reshape(input_batch, [batch_size, seq_length])
y_batch = np.reshape(output_batch, [batch_size, seq_length])
return x_batch, y_batch
# Perform some simple tests to make sure your batch function is working properly!
test_args = (vectorized_songs, 10, 2)
if not test_batch_func_types(get_batch, test_args) or \
not test_batch_func_shapes(get_batch, test_args) or \
not test_batch_func_next_step(get_batch, test_args):
print("======\n[FAIL] could not pass tests")
else:
print("======\n[PASS] passed all tests!")
For each of these vectors, each index is processed at a single time step. So, for the input at time step 0, the model receives the index for the first character in the sequence, and tries to predict the index of the next character. At the next timestep, it does the same thing, but the RNN considers the information from the previous step, i.e., its updated state, in addition to the current input.
We can make this concrete by taking a look at how this works over the first several characters in our text:
x_batch, y_batch = get_batch(vectorized_songs, seq_length=5, batch_size=1)
for i, (input_idx, target_idx) in enumerate(zip(np.squeeze(x_batch), np.squeeze(y_batch))):
print("Step {:3d}".format(i))
print(" input: {} ({:s})".format(input_idx, repr(idx2char[input_idx])))
print(" expected output: {} ({:s})".format(target_idx, repr(idx2char[target_idx])))
The Recurrent Neural Network (RNN) model
Now we're ready to define and train a RNN model on our ABC music dataset, and then use that trained model to generate a new song. We'll train our RNN using batches of song snippets from our dataset, which we generated in the previous section.
The model is based off the LSTM architecture, where we use a state vector to maintain information about the temporal relationships between consecutive characters. The final output of the LSTM is then fed into a fully connected Dense layer where we'll output a softmax over each character in the vocabulary, and then sample from this distribution to predict the next character.
As we introduced in the first portion of this lab, we'll be using the Keras API, specifically, tf.keras.Sequential, to define the model. Three layers are used to define the model:
-
tf.keras.layers.Embedding: This is the input layer, consisting of a trainable lookup table that maps the numbers of each character to a vector withembedding_dimdimensions. -
tf.keras.layers.LSTM: Our LSTM network, with sizeunits=rnn_units. -
tf.keras.layers.Dense: The output layer, withvocab_sizeoutputs.
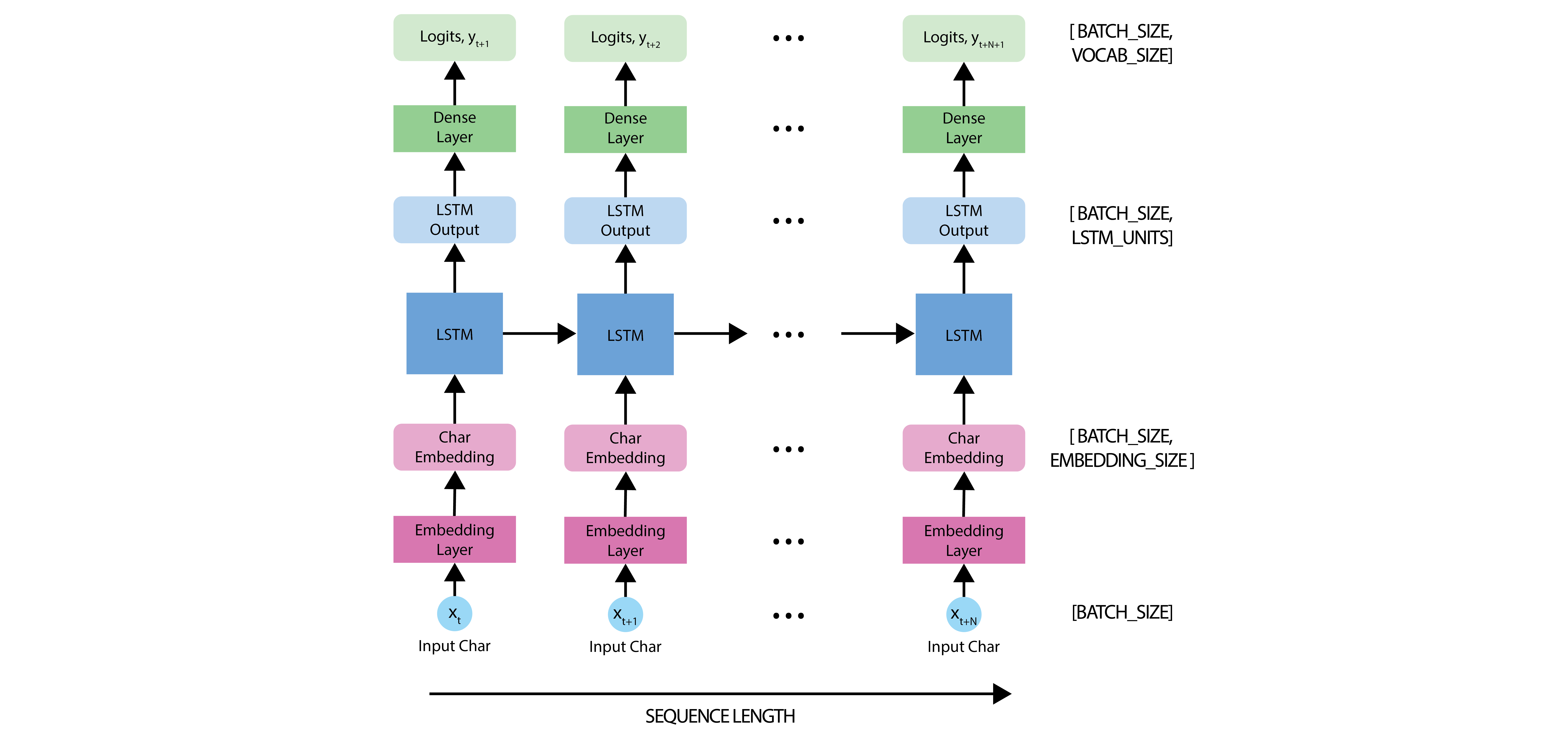
def LSTM(rnn_units):
return tf.keras.layers.LSTM(
rnn_units,
return_sequences=True,
recurrent_initializer='glorot_uniform',
recurrent_activation='sigmoid',
stateful=True,
)
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.Sequential([
# Layer 1: Embedding layer to transform indices into dense vectors
# of a fixed embedding size
tf.keras.layers.Embedding(vocab_size, embedding_dim, batch_input_shape=[batch_size, None]),
# Layer 2: LSTM with `rnn_units` number of units.
LSTM(rnn_units),
# Layer 3: Dense (fully-connected) layer that transforms the LSTM output
# into the vocabulary size.
tf.keras.layers.Dense(units=vocab_size)
])
return model
# Build a simple model with default hyperparameters. You will get the
# chance to change these later.
model = build_model(len(vocab), embedding_dim=256, rnn_units=1024, batch_size=32)
Test out the RNN model
It's always a good idea to run a few simple checks on our model to see that it behaves as expected.
First, we can use the Model.summary function to print out a summary of our model's internal workings. Here we can check the layers in the model, the shape of the output of each of the layers, the batch size, etc.
model.summary()
We can also quickly check the dimensionality of our output, using a sequence length of 100. Note that the model can be run on inputs of any length.
x, y = get_batch(vectorized_songs, seq_length=100, batch_size=32)
pred = model(x)
print("Input shape: ", x.shape, " # (batch_size, sequence_length)")
print("Prediction shape: ", pred.shape, "# (batch_size, sequence_length, vocab_size)")
Predictions from the untrained model
Let's take a look at what our untrained model is predicting.
To get actual predictions from the model, we sample from the output distribution, which is defined by a softmax over our character vocabulary. This will give us actual character indices. This means we are using a categorical distribution to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep.
Note here that we sample from this probability distribution, as opposed to simply taking the argmax, which can cause the model to get stuck in a loop.
Let's try this sampling out for the first example in the batch.
sampled_indices = tf.random.categorical(pred[0], num_samples=1)
sampled_indices = tf.squeeze(sampled_indices,axis=-1).numpy()
sampled_indices
We can now decode these to see the text predicted by the untrained model:
print("Input: \n", repr("".join(idx2char[x[0]])))
print()
print("Next Char Predictions: \n", repr("".join(idx2char[sampled_indices])))
As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? We can train the network!
Training the model: loss and training operations
Now it's time to train the model!
At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.
To train our model on this classification task, we can use a form of the crossentropy loss (negative log likelihood loss). Specifically, we will use the sparse_categorical_crossentropy loss, as it utilizes integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the labels -- and the predicted targets -- the logits.
Let's first compute the loss using our example predictions from the untrained model:
'''TODO: define the loss function to compute and return the loss between
the true labels and predictions (logits). Set the argument from_logits=True.'''
def compute_loss(labels, logits):
loss = tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
return loss
'''TODO: compute the loss using the true next characters from the example batch
and the predictions from the untrained model several cells above'''
example_batch_loss = compute_loss(y, pred)
print("Prediction shape: ", pred.shape, " # (batch_size, sequence_length, vocab_size)")
print("scalar_loss: ", example_batch_loss.numpy().mean())
Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!
# Optimization parameters:
num_training_iterations = 2000 # Increase this to train longer
batch_size = 4 # Experiment between 1 and 64
seq_length = 100 # Experiment between 50 and 500
learning_rate = 5e-3 # Experiment between 1e-5 and 1e-1
# Model parameters:
vocab_size = len(vocab)
embedding_dim = 256
rnn_units = 1024 # Experiment between 1 and 2048
# Checkpoint location:
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "my_ckpt")
Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are Adam and Adagrad.
First, we will instantiate a new model and an optimizer. Then, we will use the tf.GradientTape method to perform the backpropagation operations.
We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss.
class PeriodicPlotter:
def __init__(self, sec, xlabel='', ylabel='', scale=None):
self.xlabel = xlabel
self.ylabel = ylabel
self.sec = sec
self.scale = scale
self.tic = time.time()
def plot(self, data):
if time.time() - self.tic > self.sec:
plt.cla()
if self.scale is None:
plt.plot(data)
elif self.scale == 'semilogx':
plt.semilogx(data)
elif self.scale == 'semilogy':
plt.semilogy(data)
elif self.scale == 'loglog':
plt.loglog(data)
else:
raise ValueError("unrecognized parameter scale {}".format(self.scale))
plt.xlabel(self.xlabel); plt.ylabel(self.ylabel)
ipythondisplay.clear_output(wait=True)
ipythondisplay.display(plt.gcf())
self.tic = time.time()
'''TODO: instantiate a new model for training using the `build_model`
function and the hyperparameters created above.'''
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size)
'''TODO: instantiate an optimizer with its learning rate.
Checkout the tensorflow website for a list of supported optimizers.
https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/
Try using the Adam optimizer to start.'''
optimizer = tf.keras.optimizers.Adam(learning_rate)
@tf.function
def train_step(x, y):
# Use tf.GradientTape()
with tf.GradientTape() as tape:
'''TODO: feed the current input into the model and generate predictions'''
y_hat = model(x)
'''TODO: compute the loss!'''
loss = compute_loss(y, y_hat)
# Now, compute the gradients
'''TODO: complete the function call for gradient computation.
Remember that we want the gradient of the loss with respect all
of the model parameters.
HINT: use `model.trainable_variables` to get a list of all model
parameters.'''
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the optimizer so it can update the model accordingly
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return loss
##################
# Begin training!#
##################
history = []
plotter = PeriodicPlotter(sec=2, xlabel='Iterations', ylabel='Loss')
if hasattr(tqdm, '_instances'): tqdm._instances.clear() # clear if it exists
for iter in tqdm(range(num_training_iterations)):
# Grab a batch and propagate it through the network
x_batch, y_batch = get_batch(vectorized_songs, seq_length, batch_size)
loss = train_step(x_batch, y_batch)
# Update the progress bar
history.append(loss.numpy().mean())
plotter.plot(history)
# Update the model with the changed weights!
if iter % 100 == 0:
model.save_weights(checkpoint_prefix)
# Save the trained model and the weights
model.save_weights(checkpoint_prefix)

Generate music using the RNN model
Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).
Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a softmax over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.
Then, all we have to do is write it to a file and listen!
Restore the latest checkpoint
To keep this inference step simple, we will use a batch size of 1. Because of how the RNN state is passed from timestep to timestep, the model will only be able to accept a fixed batch size once it is built.
To run the model with a different batch_size, we'll need to rebuild the model and restore the weights from the latest checkpoint, i.e., the weights after the last checkpoint during training:
model = build_model(vocab_size, embedding_dim, rnn_units, batch_size=1)
# Restore the model weights for the last checkpoint after training
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))
model.summary()
Notice that we have fed in a fixed batch_size of 1 for inference.
The prediction procedure
Now, we're ready to write the code to generate text in the ABC music format:
-
Initialize a "seed" start string and the RNN state, and set the number of characters we want to generate.
-
Use the start string and the RNN state to obtain the probability distribution over the next predicted character.
-
Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.
-
At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.
Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?
def generate_text(model, start_string, generation_length=1000):
# Evaluation step (generating ABC text using the learned RNN model)
'''TODO: convert the start string to numbers (vectorize)'''
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
# Empty string to store our results
text_generated = []
# Here batch size == 1
model.reset_states()
tqdm._instances.clear()
for i in tqdm(range(generation_length)):
predictions = model(input_eval)
# Remove the batch dimension
predictions = tf.squeeze(predictions, 0)
'''TODO: use a multinomial distribution to sample'''
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# Pass the prediction along with the previous hidden state
# as the next inputs to the model
input_eval = tf.expand_dims([predicted_id], 0)
'''TODO: add the predicted character to the generated text!'''
# Hint: consider what format the prediction is in vs. the output
text_generated.append(idx2char[predicted_id])
return (start_string + ''.join(text_generated))
'''TODO: Use the model and the function defined above to generate ABC format text of length 1000!
As you may notice, ABC files start with "X" - this may be a good start string.'''
generated_text = generate_text(model, start_string="X", generation_length=1000) # TODO
generated_songs = extract_song_snippet(generated_text)
for i, song in enumerate(generated_songs):
# Synthesize the waveform from a song
waveform = play_song(song)
# If its a valid song (correct syntax), lets play it!
if waveform:
print("Generated song", i)
ipythondisplay.display(waveform)
Experiment and get awarded for the best songs!
Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.
Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:
- How does the number of training epochs affect the performance?
- What if you alter or augment the dataset?
- Does the choice of start string significantly affect the result?
Try to optimize your model and submit your best song! MIT students and affiliates will be eligible for prizes during the IAP offering. To enter the competition, MIT students and affiliates should upload the following to the course Canvas:
- a recording of your song;
- iPython notebook with the code you used to generate the song;
- a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.
You can also tweet us at @MITDeepLearning a copy of the song! See this example song generated by a previous 6.S191 student (credit Ana Heart): song from May 20, 2020.
Have fun and happy listening!
