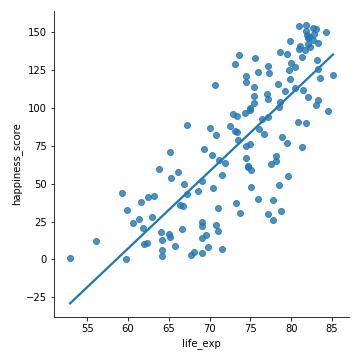
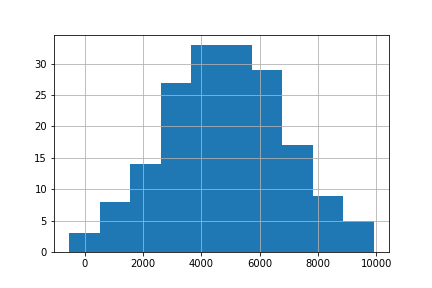
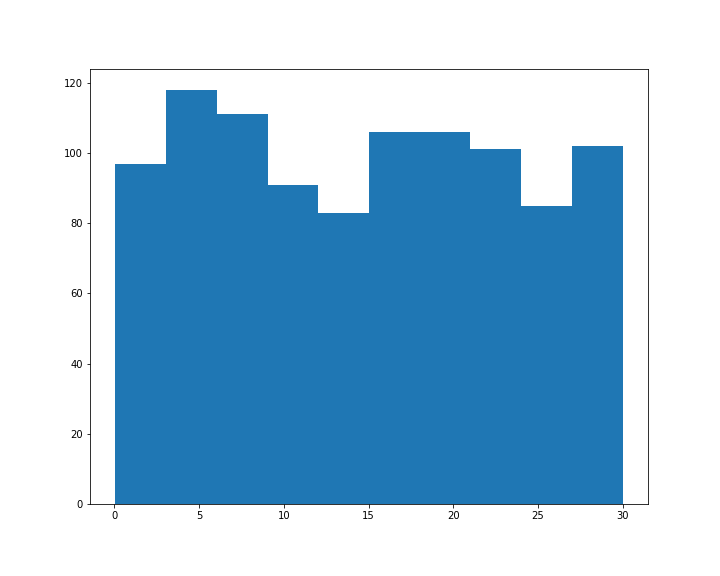
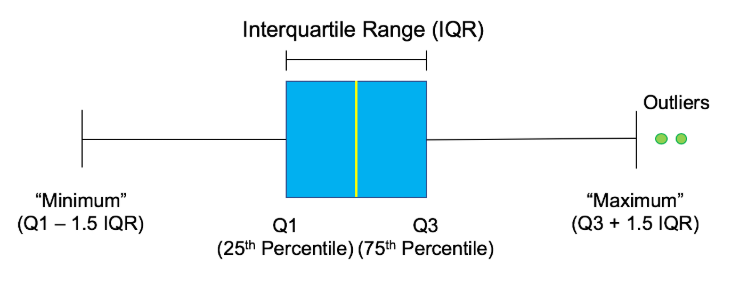
The Rebrickable database includes data on every LEGO set that ever been sold; the names of the sets, what bricks they contain, what color the bricks are, etc. It might be small bricks, but this is big data! In this project, you will get to explore the Rebrickable database. To do this you need to know your way around pandas dataframes This is the Result of Project "Exploring 67 years of LEGO", via datacamp.
Aug 17, 2020