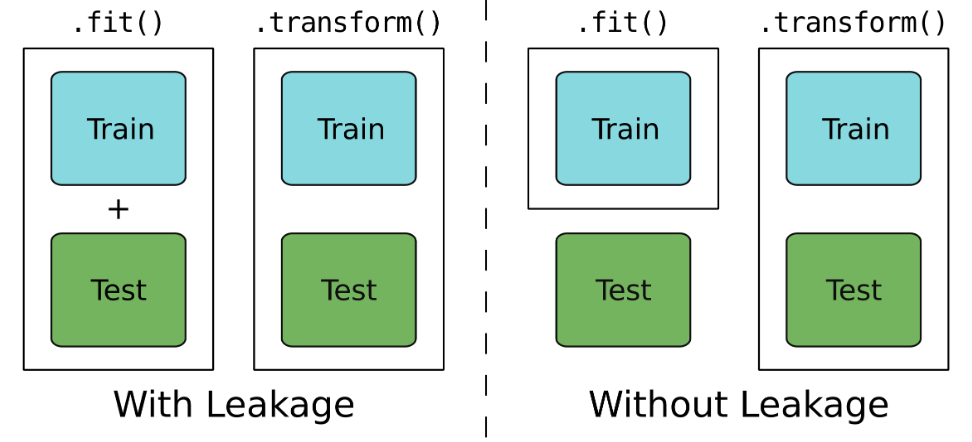
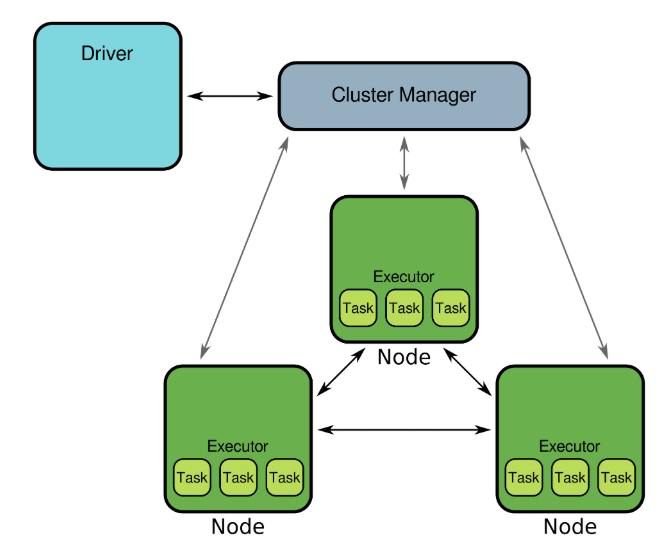
In this first chapter, you will get exposure to the Kaggle competition process. You will train a model and prepare a csv file ready for submission. You will learn the difference between Public and Private test splits, and how to prevent overfitting. This is the Summary of lecture "Winning a Kaggle Competition in Python", via datacamp.
Aug 12, 2020